C#
Getting Started
-
In Visual Studio, right-click on the desired project and select the menu to add a Nuget dependency.
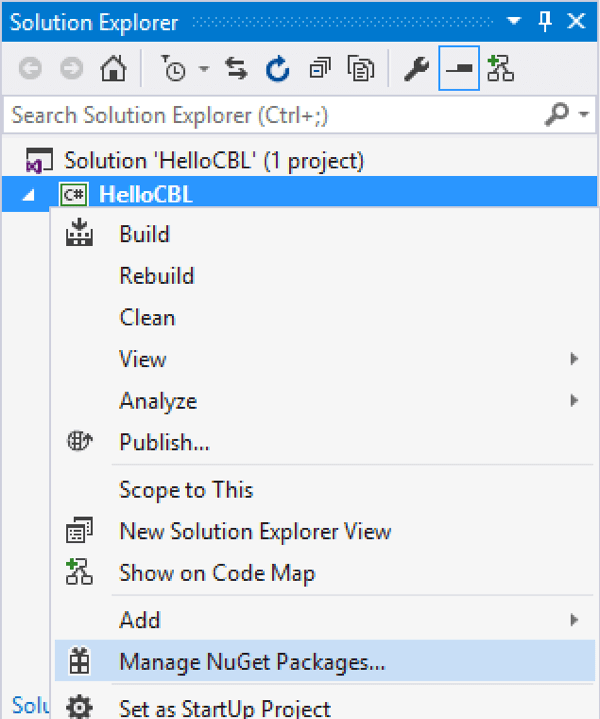
-
Search for 'Couchbase Lite' and select the latest version of the Couchbase.Lite package.
-
Once Couchbase Lite is installed you can run the project with Couchbase Lite as a dependency.
Available packages
The following libraries are available.
| Package Name | Server |
|---|---|
|
To use SQLite as the storage type. This is the default. |
|
To use SQLCipher as the storage type. |
|
To use ForestDB as the storage type. |
-
In Xamarin Studio, right-click on the desired project and select the menu to add a Nuget dependency.
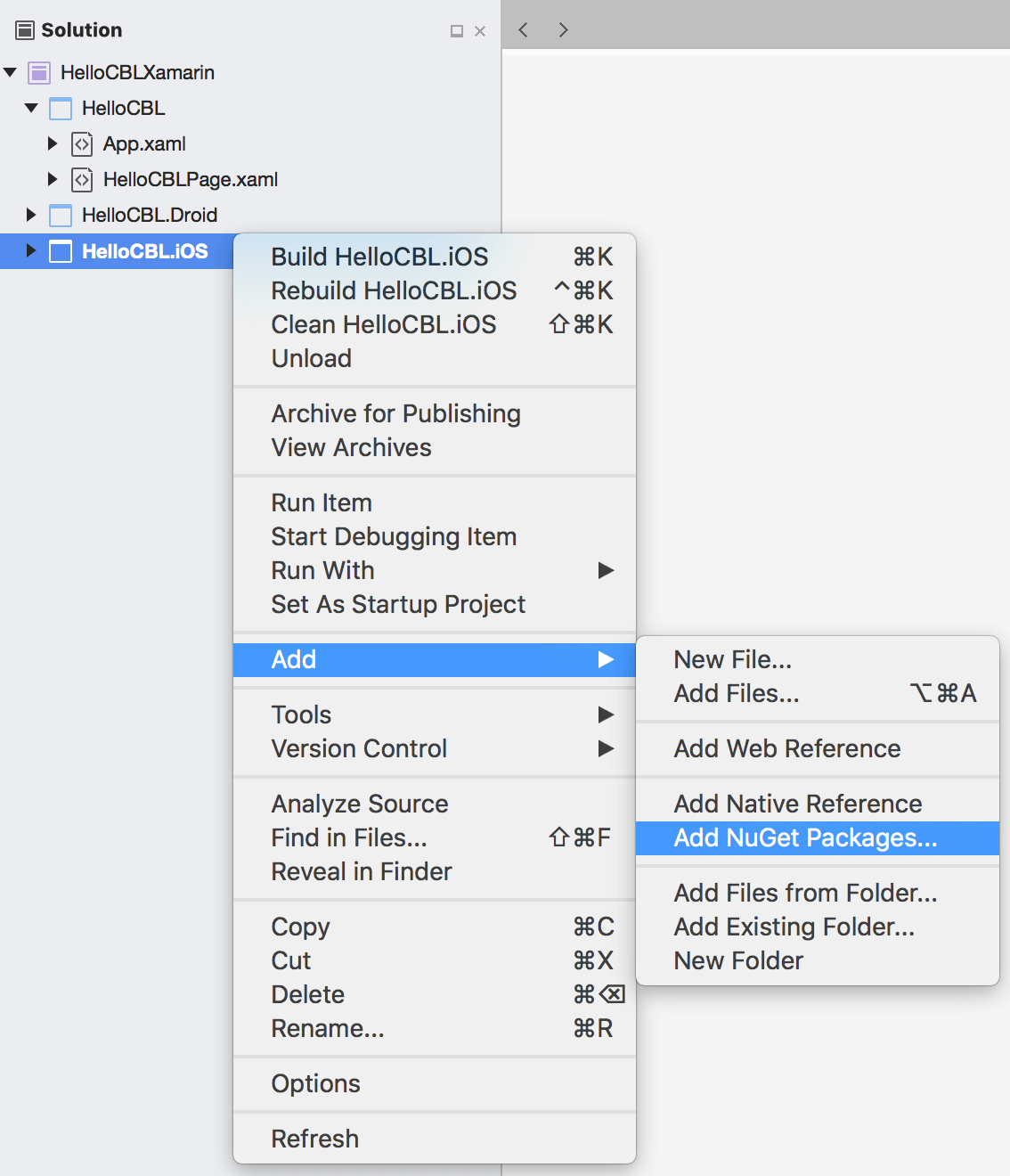
-
Search for 'Couchbase Lite' and select the latest version of the Couchbase.Lite package.
-
Once Couchbase Lite is installed you can run the project with Couchbase Lite as a dependency.
Available packages
The following libraries can be used in a Xamarin Studio project to import different components.
| Package Name | Server |
|---|---|
|
To use SQLite as the storage type. This is the default storage type. |
|
To use SQLCipher as the storage type. |
|
To use ForestDB as the storage type. |
Starter code
-
Create a new Visual Studio project and install Couchbase Lite by following the steps above.
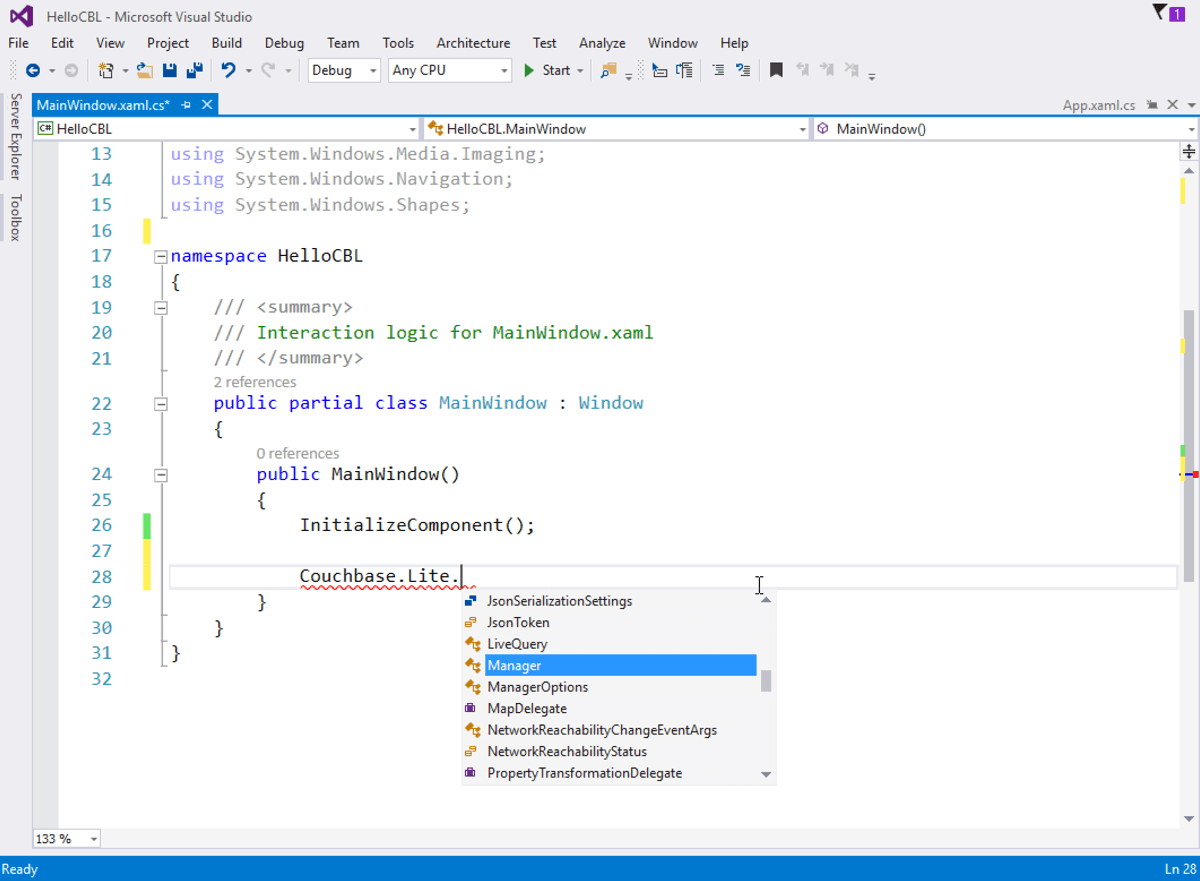
-
Open the main file in your project and add the following.
// Create a manager Manager manager = Manager.SharedInstance; // Create or open the database named app Database database = manager.GetDatabase(app); // The properties that will be saved on the document Dictionarystring, object properties = new Dictionarystring, object { { title, Couchbase Mobile}, { sdk, C# } }; // Create a new document Document document = database.CreateDocument(); // Save the document to the database document.PutProperties(properties); // Log the document ID (generated by the database) // and properties Console.WriteLine($Document ID :: {document.Id}); Console.WriteLine($Learning {document.GetProperty(title)} with {document.GetProperty(sdk)}); // Create replicators to push pull changes to from Sync Gateway. Uri url = new Uri(http://localhost:4984/hello); Replication push = database.CreatePushReplication(url); Replication pull = database.CreatePullReplication(url); push.Continuous = true; pull.Continuous = true; // Start replicators push.Start(); pull.Start(); Console.ReadKey(); -
Build and run.
-
Notice the document ID and property are printed to the console. The document was successfully persisted to the database.
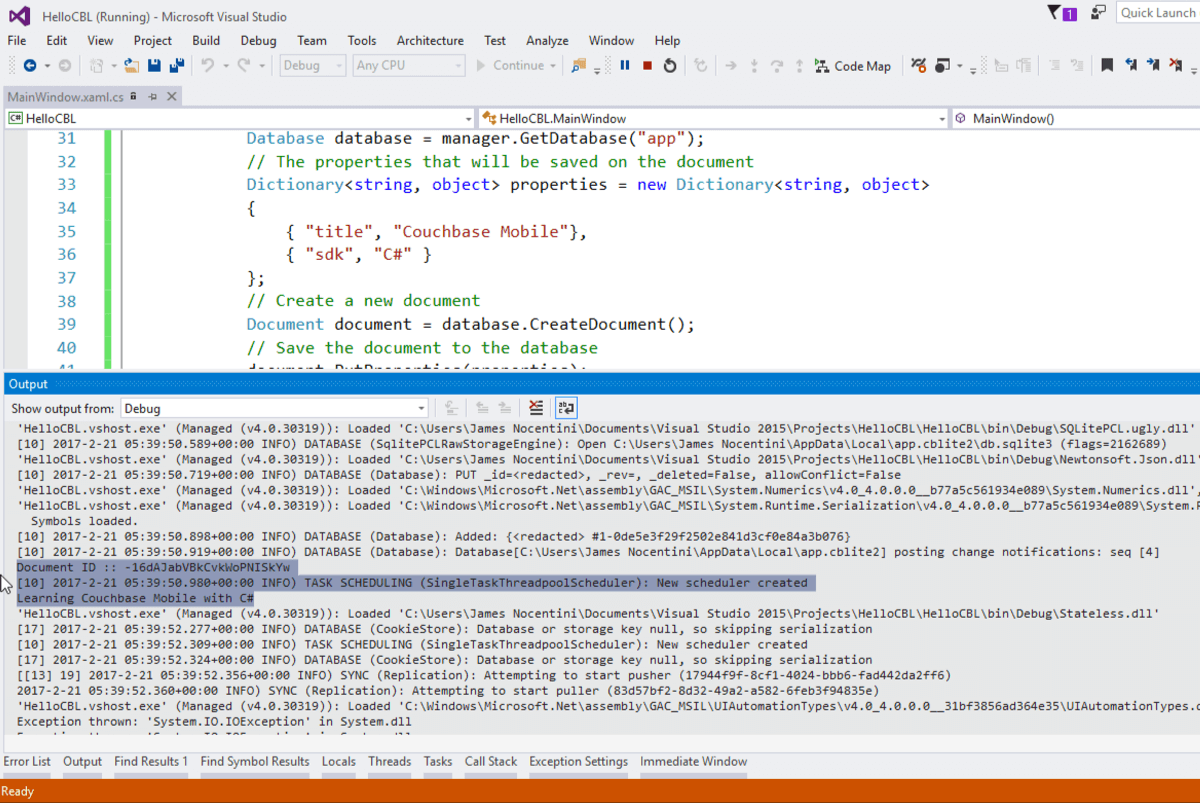
-
Create a new Xamarin Forms project in Xamarin Studio. Make sure to select the Use Shared Library option.
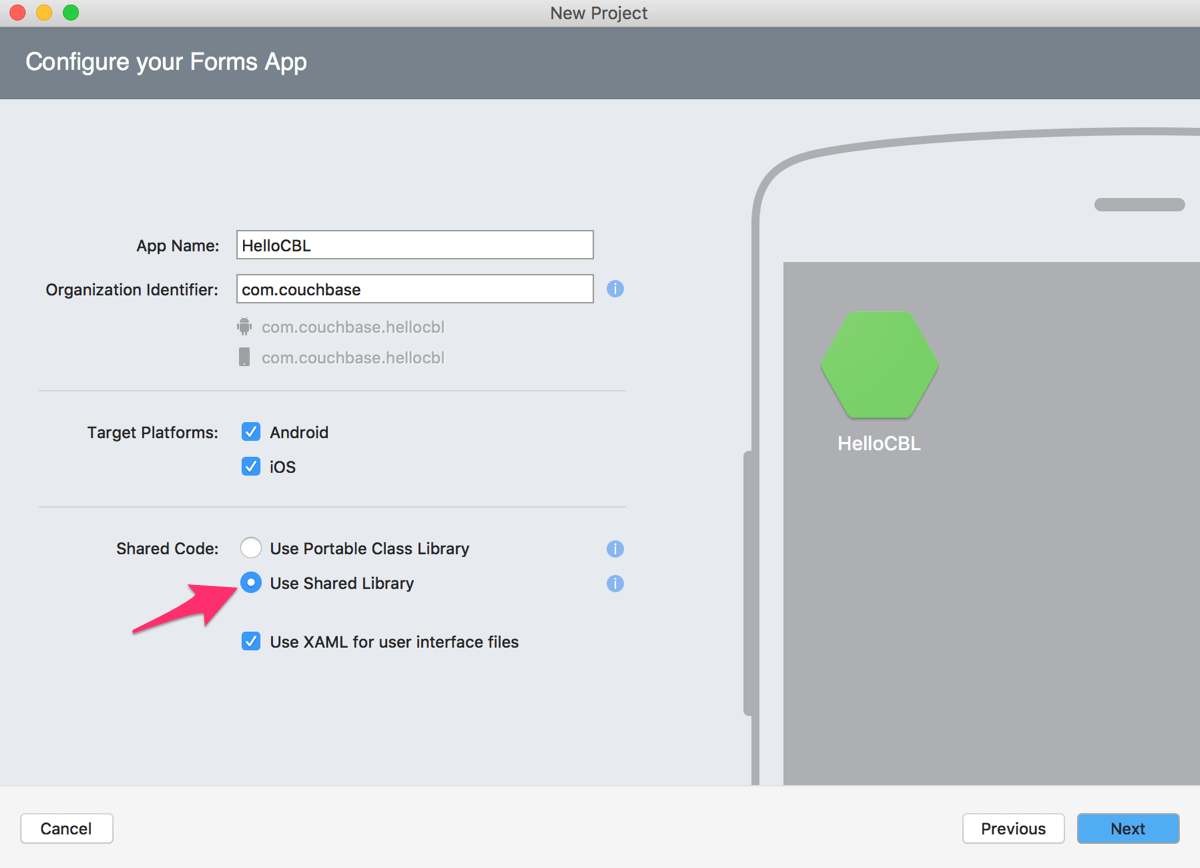
-
Right-click the iOS project and add the Couchbase Lite dependency as a Nuget package. Repeat the same steps for the Droid project.
image:xamarin-nuget.png
-
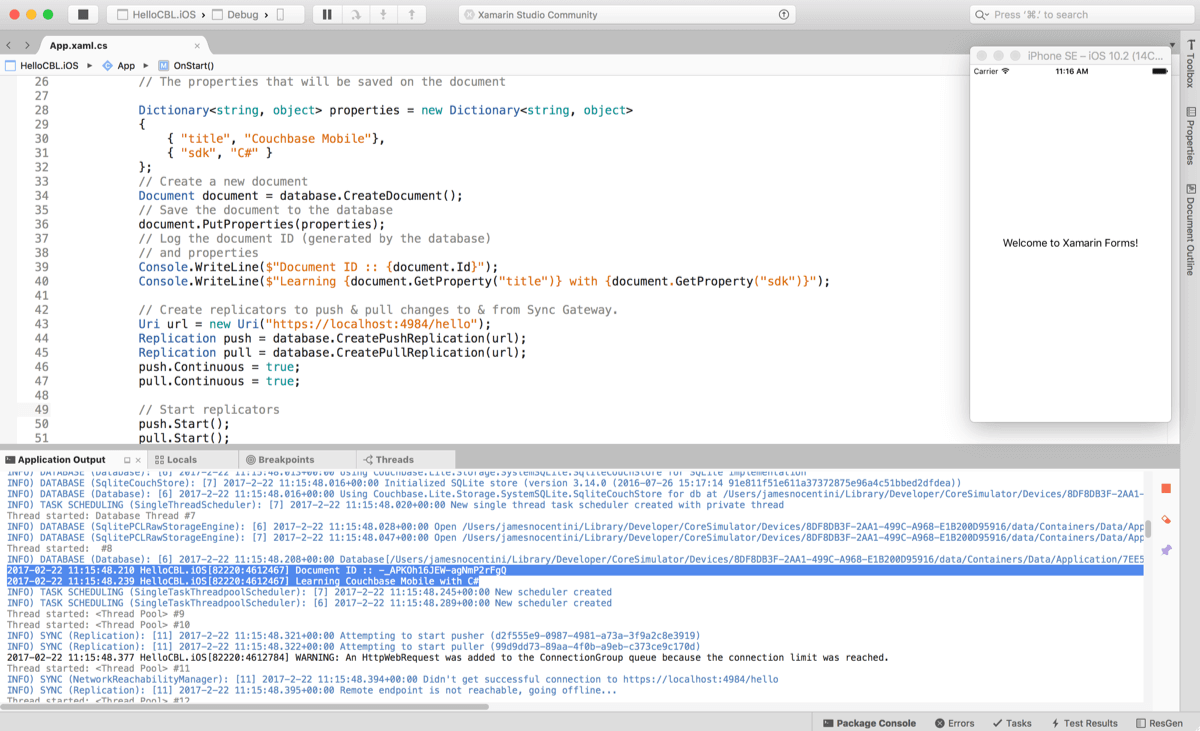
Open App.xaml.cs in Xamarin Studio and add the following in the
OnStartmethod./* This line is required for iOS only */ Couchbase.Lite.Storage.SystemSQLite.Plugin.Register(); /* Create a manager */ Manager manager = Manager.SharedInstance; /* Create or open the database named app */ Database database = manager.GetDatabase(app); /* The properties that will be saved on the document */ Dictionarystring, object properties = new Dictionarystring, object { { title, Couchbase Mobile}, { sdk, C# } }; /* Create a new document */ Document document = database.CreateDocument(); /* Save the document to the database */ document.PutProperties(properties); /* Log the document ID (generated by the database) and properties */ Console.WriteLine($Document ID :: {document.Id}); Console.WriteLine($Learning {document.GetProperty(title)} with {document.GetProperty(sdk)}); /* Create replicators to push pull changes to from Sync Gateway. */ Uri url = new Uri(http://localhost:4984/hello); Replication push = database.CreatePushReplication(url); Replication pull = database.CreatePullReplication(url); push.Continuous = true; pull.Continuous = true; /* Start replicators */ push.Start(); pull.Start(); -
Build and run.
-
Notice the document ID and property are printed to the console. The document was successfully persisted to the database.
Supported Versions
The following table lists out the supported platforms.
| .NET Runtime | Minimum Runtime Version | Minimum OS version |
|---|---|---|
.NET Framework |
3.5 |
XP |
Mono Mac |
5.2* |
10.9 |
Mono Linux |
5.2* |
n/a** |
Xamarin iOS |
8.0* |
8.0 |
Xamarin Android |
4.6* |
2.3 (API 9) |
* These runtime versions are approximate. Couchbase Lite 1.x is built using relatively new versions of all of these and an absolute minimum is unclear, and cannot actually be determined anymore due to lack of vendor support (i.e., Xamarin iOS 8 uses Xcode 6, etc). So basically "any version" is an approximately good metric here.
** See above note about Linux
Manager
A Manager is the top-level object that manages a collection of Couchbase Lite Database instances.
You need to create a Manager instance before you can work with Couchbase Lite objects in your Application.
Creating a manager
You create a Manager object by calling a constructor or initializer on the Manager class.
var manager = Manager.SharedInstance;Default database path
The Manager creates a directory in the filesystem and stores databases inside it. Normally, you don’t need to care where that is — your application shouldn’t be directly accessing those files. But sometimes it does matter. Depending on the platform you are developing for, the default database path will be:
| Platform | Path |
|---|---|
Windows (WPF) |
C:<username>\ |
Unix |
~/.local/share/ |
Xamarin Android |
/data/data/ |
var options = new ManagerOptions();
options.ReadOnly = true;
Manager manager = new Manager(Directory.CreateDirectory(dbPath), options);Global logging settings
You can customize the global logging settings for Couchbase Lite via the Manager class.
Log messages are tagged, allowing them to be logically grouped by activity.
You can control whether individual tag groups are logged.
The available tags are:
Log tags
Log.Domains.Database
Log.Domains.Query
Log.Domains.View
Log.Domains.Router
Log.Domains.Sync
Log.Domains.ChangeTracker
Log.Domains.Validation
Log.Domains.Upgrade
Log.Domains.Listener
Log.Domains.Discovery
Log.Domains.TaskScheduling
Log.Domains.All
Log levels
Log.LogLevel.Verbose
Log.LogLevel.Debug
Log.LogLevel.Error
Log.LogLevel.Warning
Log.LogLevel.InformationThe following code snippet enables logging for the Sync tag.
Log.Domains.Sync.Level = Log.LogLevel.VerboseConcurrency Support
| In Java all Couchbase Lite objects may be shared freely between threads. The rest of this section is irrelevant for Java programs, and applies only to Objective-C. |
In Objective-C, a Manager instance and the object graph associated with it may only be accessed from the thread or dispatch queue that created the Manager instance.
Concurrency is supported through explicit method calls.
Database
A Database is a container and a namespace for documents, a scope for queries, and the source and target of replication.
Databases are represented by the Database class.
Most applications only need one database, but you can use the Manager to create as many as you need. Multiple databases are independent of each other. If your application supports switching between multiple users, each with their own separate content and settings, you should consider using a database for each user. Otherwise, it’s usually best to stick with one database.
| A database is not a table. Couchbase Lite doesn’t have any equivalent of relational database tables: different types of documents all coexist in the same database. Usually you use a "type" property to distinguish them. |
A database has the following elements:
-
Its name. The name must consist only of lowercase ASCII letters, digits, and the special characters
_$()+-/. It must also be less than 240 bytes and start with a lower case letter. -
Documents. Each document is identified uniquely by its ID.
-
Views. Each view has a unique name, and a persistent index as well as map and reduce functions.
-
Filter functions. These are used to replicate subsets of documents.
-
Replications. Each replication specifies a remote database to sync documents to or from, and other parameters.
Creating a database
Creating an empty database
You create a new empty database by simply accessing it, using the databaseNamed method — this method opens the database if it isn’t yet open, and creates it if it doesn’t yet exist.
See the next section, Opening a database, for details.
This way you don’t have to write any special code for the first launch of the app.
Pulling down a remote database
Often you’ll want to create a local clone (or subset) of a database on a server. To do this you simply create an empty database as above, then start a pull replication that will download the remote database into it. The replication is asynchronous, but you can monitor its progress to find out when it’s done.
| If possible, avoid blocking until the replication completes. The user’s first-launch experience will be much more pleasant if s/he can begin using your app immediately instead of staring at a modal progress screen waiting for downloads to complete. If you’ve implemented a data-driven UI, the content will appear incrementally as it downloads. For example, the ToDoLite app initially displays no content, but the to-do lists and their items quickly appear as the replication progresses. |
Installing a pre-built database
If your app needs to sync a lot of data initially, but that data is fairly static and won’t change much, it can be a lot more efficient to bundle a database in your application and install it on the first launch. Even if some of the content changes on the server after you create the app, the app’s first pull replication will bring the database up to date.
| This is essentially trading setup time for app installation time. If you install a 100MB database in your app, that of course adds to the time it takes to download and install the app. But it can still be faster than replication since the 100MB database will simply be downloaded in bulk as part of the app archive, instead of going through the interactive sync protocol. Also, the download happens when the user expects it to (while installing the app) rather than when s/he’s not (on first launch). |
To use a prebuilt database, you need to set up the database, build the database into your app bundle as a resource, and install the database during the initial launch.
Setting Up the Database:
You need to make the database as small as possible.
Couchbase Lite keeps a revision history of every document and that takes up space.
When creating the database locally, you can make it smaller by storing each document (via a PUT request) only once, rather than updating it multiple times.
(You can double-check this by verifying that each document revision ID starts with 1-.)
If you start with a snapshot of a live database from a server, then create a new, empty local database and replicate the source database into it.
| On iOS / Mac OS, the Couchbase Lite Xcode project has a target called LiteServ that builds a small Mac app that does nothing but run the REST API. LiteServ is a useful tool for creating databases and running replications locally on your development machine. |
Extracting and Building the Database:
Next you need to find the database’s files.
The location of these is determined by the Manager instance;
it’s in a directory called CouchbaseLite whose default location is platform-specific.
(On iOS and Mac OS, it’s in the Application Support directory.)
The main database file has a .cblite extension.
If your database has attachments, you also need the "databasename attachments" directory that’s adjacent to it.
| iOS/Mac specific instructions: Add the database file and the corresponding attachments directory to your Xcode project. If you add the attachments folder, make sure that in the Add Files sheet you select the Create folder references for any added folders radio button, so that the folder structure is preserved; otherwise, the individual attachment files are all added as top-level bundle resources. |
Installing the Database: After your app launches and creates a Database instance for its database, it needs to check whether the database exists. If the database does not exist, the app should copy it from the app bundle. The code looks like this:
No code example is currently available.Opening a database
You’ll typically open a database while initializing your app, right after instantiating the Manager object, and store a reference to the Database object as either a global variable or a property of your top-level application object (the app delegate on iOS or Mac OS).
Opening a database is as simple as calling the Manager’s databaseNamed method — this will first create a new empty database if one doesn’t already exist with that name.
It’s fine to call this method more than once.
It will return the same Database instance every time.
For compatibility reasons, database names cannot contain uppercase letters!
The only legal characters are lowercase ASCII letters, digits, and the special characters \_$()+-/
|
var db = Manager.SharedInstance.GetDatabase("my-database");
if (db == null)
{
Log.E(Tag, "Cannot create database");
}
If you want to open only an existing database, without the possibility of creating a new one, call the related Manager method existingDatabaseNamed instead.
It returns null/nil (without an error or exception) if no database with that name exists.
|
Database encryption
Since Couchbase Lite 1.2, databases can be encrypted using SQLCipher; an open source extension to SQLite that provides transparent encryption of database files. The encryption specification is 256-bit AES. The steps below outline how to enable it.
Step 1: Installing SQLCipher
SQLCipher is an optional dependency. The section below describes how to add it on each platform.
Windows
-
Install the Nuget package called
Couchbase.Lite.Storage.SQLCipher -
Alternatively, if you are manually adding the DLLs to the Visual Studio project, you should include
sqlcipher.dllandCouchbase.Lite.Storage.SQLCipher.dll
Then call Couchbase.Lite.Storage.SQLCipher.Plugin.Register() in the application.
Step 2: Enabling encryption
At this point, Couchbase Lite won’t work any differently. Databases are still unencrypted by default. To enable encryption, you must register an encryption key when opening the database with the openDatabase method.
var key = new SymmetricKey("password123456");
var options = new DatabaseOptions
{
EncryptionKey = key,
Create = true,
StorageType = StorageEngineTypes.SQLite
};
Database database = manager.OpenDatabase("db", options);If the database does not exist (and options.create is true) it will be created encrypted with the given key.
If the database already exists, the key will be used to decrypt it (and to encrypt future changes). If the key does not match the one previously used, opening the database will fail; the error/exception will have status code 401.
To change the encryption key, you must first open the database using the openDatabase method with the existing key and if the operation is successful, use the changeEncryptionKey method providing the new key.
Passing nil as the value will disable encryption.
Storage engines
| The following section describes how to set up ForestDB, which will be deprecated in the next major release of Couchbase Mobile. For present and future development, we recommend to use the default storage type, SQLite. |
There are two storage engines available with Couchbase Lite: SQLite and ForestDB. In the case of SQLite, it will use the system dependency already available on most platforms (iOS, Android, Windows…). To use ForestDB, the project must include the ForestDB storage dependency (see instructions below).
What is ForestDB?
ForestDB is a persistent key-value storage library, it’s a key-value map where the keys and values are binary blobs.
Choosing a storage engine
For new databases
At runtime, you need to tell the Manager you want to use ForestDB, by setting its storageType to ForestDB.
Manager manager = Manager.SharedInstance;
manager.StorageType = "ForestDB";This only applies to new databases. Existing local database files will always open with the same storage engine that created them.
Upgrading databases to ForestDB
It’s possible to upgrade an existing local database file from SQLite to ForestDB. You can use this option if you have an already-shipping app and want your existing installs to use ForestDB as well as new installs. To do this, you use an alternate method to open your database, one that allows you to specify a set of options.
Manager manager = Manager.SharedInstance;
DatabaseOptions options = new DatabaseOptions();
options.Create = true;
options.StorageType = "ForestDB";
Database database = manager.OpenDatabase ("my-database", options);Setting the options' storageType property forces the database to use the ForestDB format.
If it’s currently in SQLite format, it will be converted in place before being opened.
(The next time, it will just open normally, since it’s already ForestDB.)
Database notifications
You can register for notifications when documents are added/updated/deleted from a database. In practice, applications don’t use these as much as live queries and document change notifications; still this facility can be useful if you want a lightweight way to tell whenever anything’s changed in a database.
database.Changed += (sender, e) => {
var changes = e.Changes.ToList();
foreach (DocumentChange change in changes) {
Log.D(Tag, "Document changed, revision ID " + change.RevisionId);
}
};The example above shows how to access the revision linked to the document change that is being processed. The notifications may not be delivered immediately after the document changes. Notifications aren’t delivered during a transaction; they’re buffered up for delivery after the transaction completes.
Database housekeeping
Refer to the Revisions guide to learn about compaction and pruning to manage the database size.
Deleting a database
The delete method (deleteDatabase in Objective-C) permanently deletes a database’s file and all its attachments.
After this, you should immediately set your Database reference to nil/null and not call it again.
try {
database.Delete();
} catch (CouchbaseLiteException e) {
Log.E(Tag, "Cannot delete database", e);
}Document
In a document database such as Couchbase Lite, the primary entity stored in a database is called a document instead of a "row" or "record". This reflects the fact that a document can store more data, with more structure, than its equivalent in other databases.
In Couchbase Lite, a document’s body takes the form of a JSON object — a collection of key/value pairs where the values can be different types of data such as numbers, strings, arrays or even nested objects. Every document is identified by a document ID, which can be automatically generated (as a UUID) or determined by the application; the only constraints are that it must be unique within the database, and it can’t be changed.
In addition, a document can contain attachments, named binary blobs that are useful for storing large media files or other non-textual data. Couchbase Lite supports attachments of unlimited size, although the Sync Gateway currently imposes a 20MB limit for attachments synced to it.
Couchbase Lite keeps track of the change history of every document, as a series of revisions. This is somewhat like a version control system such as Git or Subversion, although its main purpose is not to be able to access old data, but rather to assist the replicator in deciding what data to sync and what documents have conflicts. Every time a document is created or updated, it is assigned a new unique revision ID. The IDs of past revisions are available, and the contents of past revisions may be available, but only if the revision was created locally and the database has not yet been compacted.
To summarize, a document has the following attributes:
-
A document ID
-
A current revision ID (which changes every time the document is updated)
-
A history of past revision IDs (usually linear, but will form a branching tree if the document has or has had conflicts)
-
A body in the form of a JSON object, i.e., a set of key/value pairs
-
Zero or more named binary attachments
-
Creating, Reading, Updating and Deleting documents (CRUD)
Creating, Reading, Updating and Deleting documents (CRUD)
Couchbase Lite of course supports the typical database "CRUD" operations on documents: Create, Read, Update, Delete.
Creating documents
You can create a document with or without giving it an ID.
If you don’t need or want to define your own ID, call the Database method createDocument, and the ID will be generated randomly in the form of a Universally Unique ID (UUID), which looks like a string of hex digits.
The uniqueness ensures that there is no chance of an accidental collision by two client apps independently creating different documents with the same ID, then replicating to the same server.
The following example shows how to create a document with an automatically-assigned UUID:
var document = database.CreateDocument();
var properties = new Dictionary<string, object>()
{
{"type", "list"},
{"title", "title"},
{"created_at", DateTime.UtcNow.ToString ("o")},
{"owner", "profile:" + userId},
{"members", new List<string>()}
};
var rev = document.PutProperties(properties);
Debug.Assert(rev != null);If you do want to choose the document’s ID, just call the Database method getDocument, just as you would to retrieve an existing document.
If the document doesn’t exist yet, you still get a valid Document object, it just doesn’t have any revisions or contents yet.
The first time you save the document, it will be added persistently to the database.
If a document does already exist with the same ID, saving the document will produce a conflict error.
The following example shows how to create a document with an custom ID:
var properties = new Dictionary<string, object>
{
{"title", "Little, Big"},
{"author", "John Crowley"},
{"published", 1982}
};
var document = database.GetDocument("978-0061120053");
Debug.Assert(document != null);
var rev = document.PutProperties(properties);
Debug.Assert(rev != null);| It’s up to you whether to assign your own IDs or use random UUIDs. If the documents are representing entities that already have unique IDs — like email addresses or employee numbers — then it makes sense to use those, especially if you need to ensure that there can’t be two documents representing the same entity. For example, in a library cataloging app, you wouldn’t want two librarians to independently create duplicate records for the same book, so you might use the book’s ISBN as the document ID to enforce uniqueness. |
Reading documents
To retrieve a Document object given its ID, call the Database method getDocument.
As described in the previous section, if there is no document with this ID, this method will return a valid but empty Document object.
(If you would rather get a null/nil result for a nonexistent document, call existingDocumentWithID instead.)
Document objects, like document IDs, are unique.
That means that there is never more than one Document object in memory that represents the same document.
If you call getDocument multiple times with the same ID, you get the same Document object every time.
This helps conserve memory, and it also makes it easy to compare Document object references (pointers) — you can just use == to check whether two references refer to the same document.
Loading a Document object doesn’t immediately read its properties from the database.
Those are loaded on demand, when you call an accessor method like getProperties (or access the Objective-C property properties).
The properties are represented using whatever platform type is appropriate for a JSON object.
In Objective-C they’re an NSDictionary, in Java a Map<String,Object>.
Here’s a simple example of getting a document’s properties:
var doc = database.GetDocument(myDocId);
// We can directly access properties from the document object:
doc.GetProperty("title");
// Or go through its properties dictionary:
var owner = doc.Properties["owner"];
The getProperties method is actually just a convenient shortcut for getting the Document’s currentRevision and then getting its properties — since a document usually has multiple revisions, the properties really belong to a revision.
Every existing document has a current revision (in fact that’s how you can tell whether a document exists or not).
Almost all the time you’ll be accessing a document’s current revision, which is why the convenient direct properties accessor exists.
|
Updating documents
There are two methods that update a document: putProperties and update.
We’ll cover them both, then explain why they’re different.
putProperties is simpler: given a new JSON object, it replaces the document’s body with that object.
Actually what it does is creates a new revision with those properties and makes it the document’s current revision.
var doc = database.GetDocument(myDocId);
var p = new Dictionary<string, object>(doc.Properties)
{
{"title", title},
{"notes", notes}
};
var rev = doc.PutProperties(p);
Debug.Assert(rev != null);update instead takes a callback function or block (the details vary by language).
It loads the current revision’s properties, then calls this function, passing it an UnsavedRevision object, whose properties are a mutable copy of the current ones.
Your callback code can modify this object’s properties as it sees fit;
after it returns, the modified revision is saved and becomes the current one.
var doc = database.GetDocument(myDocId);
doc.Update((UnsavedRevision newRevision) =>
{
var properties = newRevision.Properties;
properties["title"] = title;
properties["notes"] = notes;
return true;
});Whichever way you save changes, you need to consider the possibility of update conflicts. Couchbase Lite uses Multiversion Concurrency Control (MVCC) to guard against simultaneous changes to a document. (Even if your app code is single-threaded, the replicator runs on a background thread and can be pulling revisions into the database at the same time you’re making changes.)
Here’s the typical sequence of events that creates an update conflict:
-
Your code reads the document’s current properties, and constructs a modified copy to save
-
Another thread (perhaps the replicator) updates the document, creating a new revision with different properties
-
Your code updates the document with its modified properties
Clearly, if your update were allowed to proceed, the change from step 2 would be overwritten and lost. Instead, the update will fail with a conflict error. Here’s where the two API calls differ:
-
putProperties simply returns the error to you to handle. You’ll need to detect this type of error, and probably handle it by re-reading the new properties and making the change to those, then trying again.
-
update is smarter: it handles the conflict error itself by re-reading the document, then calling your block again with the updated properties, and retrying the save. It will keep retrying until there is no conflict.
| Of the two techniques, calling update may be a bit harder to understand initially, but it actually makes your code simpler and more reliable. We recommend it. (Just be aware that your callback block can be called multiple times.) |
Deleting documents
The delete method (deleteDocument: in Objective-C) deletes a document:
var doc = database.GetDocument(myDocId);
doc.Delete();Deleting a document actually just creates a new revision (informally called a "tombstone") that has the special _deleted property set to true.
This ensures that the deletion will replicate to the server, and then to other endpoints that pull from that database, just like any other document revision.
| It’s possible for the delete call to fail with a conflict error, since it’s really just a special type of putProperties. In other words, something else may have updated the document at the same time you were trying to delete it. It’s up to your app whether it’s appropriate to retry the delete operation. |
If you need to preserve one or more fields in a document that you want to delete (like a record of who deleted it or when it was deleted) you can avoid the delete method;
just update the document and set the UnsavedRevision's `deletion property to true, or set JSON properties that include a "_deleted" property with a value of true.
You can retain all of the fields, as shown in the following example, or you can remove specified fields so that the tombstone revision contains only the fields that you need.
var doc = database.GetDocument(myDocId);
doc.Update((UnsavedRevision newRevision) =>
{
newRevision.IsDeletion = true;
newRevision.Properties["deleted_at"] = currentTimeString;
return true;
});Document expiration (TTL)
Documents in a local database can have an expiration time. After that time, they are automatically purged from the database - this completely removes them, freeing the space they occupied. This feature was introduced in Couchbase Lite 1.3.
The following example sets the TTL for a document to 5 seconds from the current time.
var doc = db.CreateDocument();
doc.PutProperties(new Dictionary<string, object> { { "foo", "bar" } });
doc.ExpireAfter(TimeSpan.FromSeconds(5));Expiration timing is not highly precise. The times are stored with one-second granularity, and the timer that triggers expiration may be delayed slightly by the operating system or by other activity on the database thread. Expiration won’t happen while the app is not running; this means it may be triggered soon after the app is activated or launched, to catch up with expiration times that have already passed.
| As with the existing explicit purge mechanism, this applies only to the local database; it has nothing to do with replication. This expiration time is not propagated when the document is replicated. The purge of the document does not cause it to be deleted on any other database. If the document is later updated on a remote database that the local database pulls from, the new revision will be pulled and the document will reappear. |
Document change notifications
You can register for notifications when a particular document is updated or deleted. This is very useful if you’re display a user interface element whose content is based on the document: use the notification to trigger a redisplay of the view.
You can use change events for the following purposes:
-
To be notified when new revisions are added to a document
-
To be notified when a document is deleted
-
To be notified when a document enters into a conflicted state
var doc = database.CreateDocument();
doc.Change += (sender, e) =>
{
var change = e.Change;
var documentId = change.DocumentId;
var revisionId = change.RevisionId;
var isConflict = change.IsConflict;
var addedRev = change.AddedRevision;
};Conflicts
So far we’ve been talking about a conflict as an error that occurs when you try to update a document that’s been updated since you read it. In this scenario, Couchbase Lite is able to stop the conflict before it happens, giving your code a chance to re-read the document and incorporate the other changes.
However, there’s no practical way to prevent a conflict when the two updates are made on different instances of the database. Neither app even knows that the other one has changed the document, until later on when replication propagates their incompatible changes to each other. A typical scenario is:
-
Molly creates DocumentA; the revision is 1-5ac
-
DocumentA is synced to Naomi’s device; the latest revision is still 1-5ac
-
Molly updates DocumentA, creating revision 2-54a
-
Naomi makes a different change to DocumentA, creating revision 2-877
-
Revision 2-877 is synced to Molly’s device, which already has 2-54a, putting the document in conflict
-
Revision 2-54a is synced to Naomi’s device, which already has 2-877, similarly putting the local document in conflict
At this point, even though DocumentA is in a conflicted state, it needs to have a current revision.
That is, when your app calls getProperties, Couchbase Lite has to return something.
It chooses one of the two conflicting revisions (2-877 and 2-54a) as the "winner".
The choice is deterministic, which means that every device that is faced with the same conflict will pick the same winner, without having to communicate.
In this case it just compares the revision IDs "2-54a" and "2-877" and picks the higher one, "2-877".
To be precise, Couchbase Lite uses the following rules to handle conflicts:
-
The winner is the undeleted leaf revision on the longest revision branch (i.e., with the largest prefix number in its revision ID).
-
If there are no undeleted leaf revisions, the deletion (tombstone) on the longest branch wins.
-
If there’s a tie, the winner is the one whose revision ID sorts higher in a simple ASCII comparison.
| Couchbase Lite does not automatically merge the contents of conflicts. Automated merging would run the risk of giving wrong or undesired results in many cases; only you know your document schemas well enough to decide how conflicts should be merged. |
In some cases this simple "one revision wins" rule is good enough. For example, in a grocery list if two people rename the same item, one of them will just see that their change got overwritten, and may do it over again. But usually the details of the document content are more important, so the application will want to detect and resolve conflicts.
| Resolving conflicts can also save the space in the database. Conflicting revisions stay in the database indefinitely until resolved, even surviving compactions. Therefore, it makes sense to deal with the conflict by at least deleting the non-winning revision. |
Another reason to resolve conflicts is to implement business rules. For example, if two sales associates update the same customer record and it ends up in conflict, you might want the sales manager to resolve the conflict and "hand merge" the two conflicting records so that no information is lost.
There are two alternative ways to resolve a conflict:
-
Pick a winner. Just decide which of the two changes should win, and delete the other one. The deleted revision will no longer be eligible as a conflict winner, so there won’t be any more conflict.
-
Merge. Consider the contents of both conflicting revisions and construct a new revision that incorporates both. The details are, of course, application-dependent, and might even require user interaction. Then resolve the conflict by saving the merged revision, then deleting the old losing conflict revision.
The following example shows how to resolve a conflict:
var doc = database.GetDocument(myDocId);
var conflicts = doc.ConflictingRevisions.ToList();
if (conflicts.Count > 1)
{
// There is more than one current revision, thus a conflict!
database.RunInTransaction(() =>
{
var mergedProps = MergeRevisions(conflicts);
var current = doc.CurrentRevision;
foreach(var rev in conflicts)
{
var newRev = rev.CreateRevision();
if (rev == current)
{
newRev.SetProperties(mergedProps);
}
else
{
newRev.IsDeletion = true;
}
// saveAllowingConflict allows 'rev' to be updated even if it
// is not the document's current revision.
newRev.SaveAllowingConflict();
}
return true;
});
}Document Conflict FAQ
What if both devices make the same change to the document? Is that a conflict?
No. The revision ID is derived from a digest of the document body. So if two databases save identical changes, they end up with identical revision IDs, and Couchbase Lite (and the Sync Gateway) treat these as the same revision.
I deleted a document, but the it’s still in the database, only now its properties are different. What happened?
Sounds like the document was in conflict and you didn’t realize it. You deleted the winning revision, but that made the other (losing) revision become the current one. If you delete the document again, it’ll actually go away.
How can I get the properties of the common ancestor revision, to do a three-way merge?
You can’t always.
Couchbase Lite isn’t a version-control system and doesn’t preserve old revision bodies indefinitely.
But if the ancestor revision used to exist in your local database, and you haven’t yet compacted the database, you can still get its properties.
Get the parentRevision property of the current revision to get the ancestor, then see if its properties are still non-null.
Purging documents
Purging a document is different from deleting it;
it’s more like forgetting it.
The purge method removes all trace of a document (and all its revisions and their attachments) from the local database.
It has no effect on replication or on remote databases, though.
Purging is mostly a way to save disk space by forgetting about replicated documents that you don’t need anymore. It has some slightly weird interactions with replication, though. For example, if you purge a document, and then later the document is updated on the remote server, the next replication will pull the document into your database again.
Special Properties
The body of a document contains a few special properties that store metadata about the document. For the most part you can ignore these since the API provides accessor methods for the same information, but it can still be helpful to know what they are if you encounter them.
_id-
The document ID.
_rev-
The revision ID.
_attachments-
Metadata about the document’s attachments.
_deleted-
Only appears in a deletion (tombstone) revision, where it has the value
true.
| A leading underscore always denotes a reserved property. Don’t use an underscore prefix for any of your own properties, and don’t change the value of any reserved property. |
Revision
Couchbase Lite uses revisions to resolve conflicts detected during replication. One significant difference from other databases is document versioning. Couchbase Lite uses a technique called Multiversion Concurrency Control (MVCC) to manage conflicts between multiple writers. This is the same technique used by version-control systems like Git or Subversion, and by WebDAV. Document versioning is similar to the check-and-set mechanism (CAS) of Couchbase Server, except that in Couchbase Lite versioning is required rather than optional and the token is a UUID rather than an integer.
Every document has a special field called _rev that contains the revision ID.
The revision ID is assigned automatically each time the document is saved.
Every time a document is updated, it gets a different and unique revision ID.
When you save an update to an existing document, you must include its current revision ID. If the revision ID you provide isn’t the current one, the update is rejected. When this happens, it means some other endpoint snuck in and updated the document before you. You need to fetch the new version, reconcile any changes, incorporate the newer revision ID, and try again.
Keep in mind that Couchbase Lite is not a version control system and you must not use the versioning feature in your application. They’re there only to help with concurrency and resolving conflicts during replication.
Resolving Conflicts
Revisions form a tree data structure since they can have multiple branches. In the case where there are multiple branches, one or more conflicts exist and should be resolved per the application requirements.
Tombstones
The reason that tombstone revisions exist is so that deletes can be sync’d to other databases. If revisions were simply deleted with a naive approach, then there would be no easy way to sync up with other databases that contained the revision.
There is a special field in a revision’s JSON called _deleted which determines whether the revision is a tombstone revision or not.
A consequence of this fact is that tombstone revisions can hold arbitrary amounts of metadata, which can be useful for an application.
If the full metadata of the document is preserved in the tombstone revision, then a document could easily be restored to it’s last known good state after it’s been deleted at some point.
For examples of deleting revisions via adding a tombstone revision, refer to the guide on Documents.
Saved vs Unsaved Revision
Here are the main differences between Saved and Unsaved Revision objects:
-
Unsaved revisions have not yet been persisted to the database.
-
Saved revisions have already been persisted to the database.
-
Unsaved revisions are useful for adding attachments.
Unsaved Revisions are mainly useful for manipulating attachments, since they provide the only means to do so via the API. See Attachments for examples of adding/removing attachments.
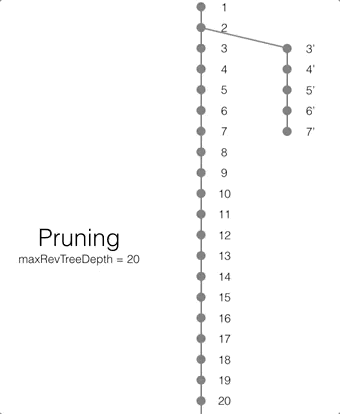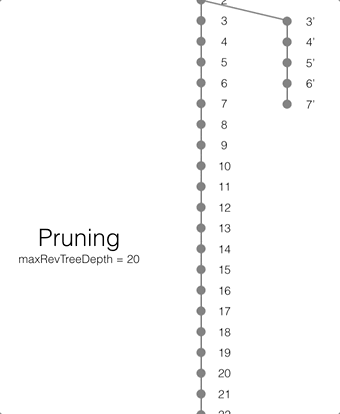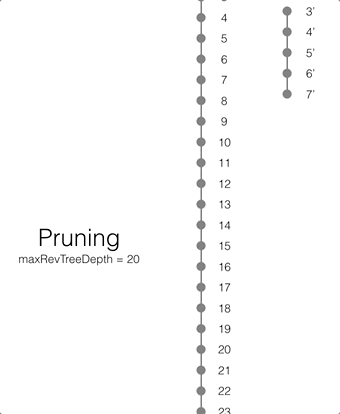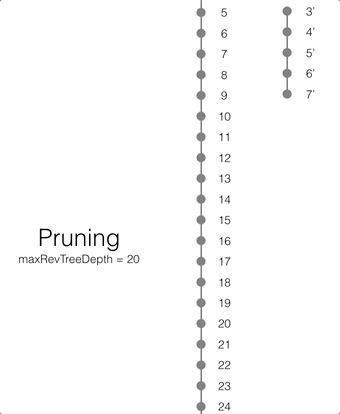
Pruning
Pruning is the process that deletes the metadata and/or JSON bodies associated with old non-leaf revisions. Leaf revisions are not impacted. The process runs automatically every time a revision is added. The maxRevTreeDepth value defaults to 20, which means that the metadata and JSON bodies of the last 20 revisions are retained in Couchbase Lite as shown on the animation below.
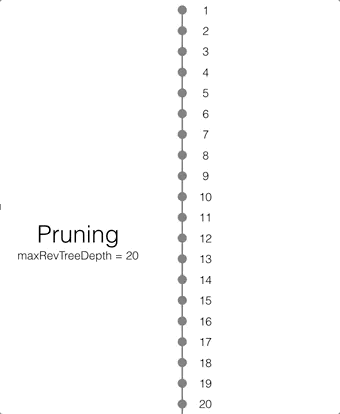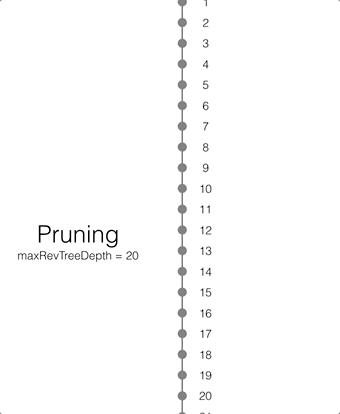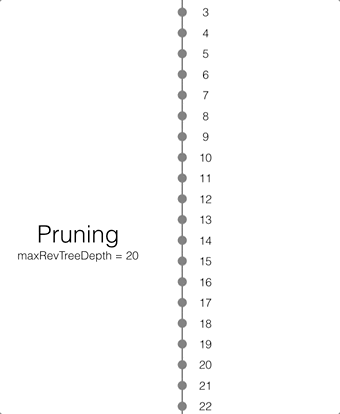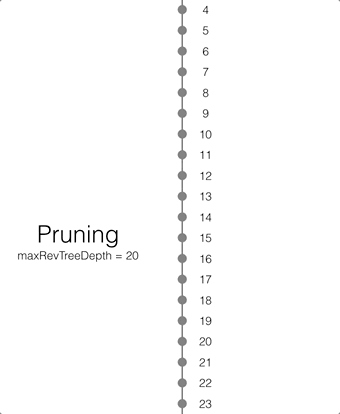
If there are conflicting revisions, the document may end up with disconnected branches after the pruning process. In the animation below, the document has a conflicting branch (revisions 3 - 7). When the current revision (or longest branch) reaches the 23rd update, the conflicting branch is cut off. The revision tree is not in a corrupted state and the logic that chooses the winning revision still applies. But it may make it impossible to do certain merges to resolve conflicts and occupy disk space that could have been free-ed if the conflict was resolved early on.
Compaction
Compaction is defined as the process of purging the JSON bodies of non-leaf revisions.
As shown on the diagram below, only properties with a leading underscore (_ is the character to denote properties reserved for Couchbase) are kept to construct the revision tree.
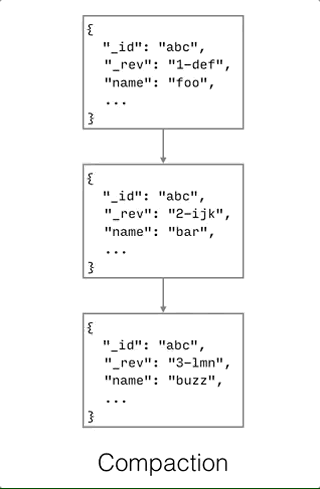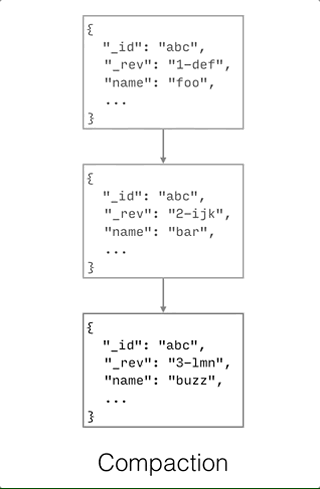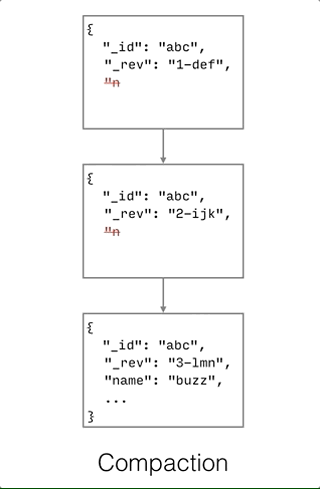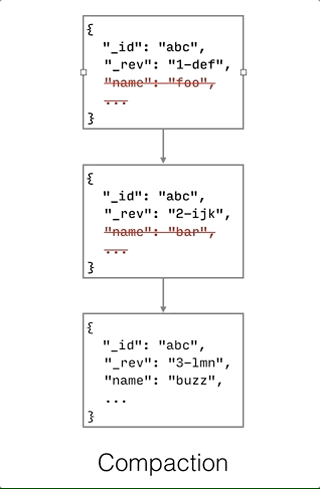
Compaction can only be invoked manually via the compact() method. The compaction process does not remove JSON bodies of leaf nodes. Hence, it is important to resolve conflicts in your application in order to re-claim disk space when the compaction process is executed.
Attachment
Attachments store data associated with a document, but are not part of the document’s JSON object. Their primary purpose is to make it efficient to store large binary data in a document. Binary data stored in JSON has to be base64-encoded into a string, which inflates its size by 33%. Also, binary data blobs are often large (think of camera images or audio files), and big JSON documents are slow to parse.
Attachments are uninterpreted data (blobs) stored separately from the JSON body.
A document can have any number of attachments, each with a different name.
Each attachment is also tagged with a MIME type, which isn’t used by Couchbase Lite but can help your application interpret its contents.
On Couchbase Lite, attachments can be arbitrarily large, and are only read on demand, not when you load a Document object.
On Sync Gateway, the maximum content size is 20 MB per attachment.
If a document’s attachment is over 20 MB, the document will be replicated but not the attachment.
Attachments also make replication more efficient. When a document that contains pre-existing attachments is synced, only attachments that have changed since the last sync are transferred over the network. In particular, changes to document JSON values will not cause Couchbase Lite to re-send attachment data when the attachment has not changed.
In the native API, attachments are represented by the Attachment class.
Attachments are available from a Revision object.
From a Document, you get to the attachments via its currentRevision.
Reading attachments
The Revision class has a number of methods for accessing attachments:
attachmentNames-
Returns the names of all the attachments.
attachmentNamed-
Returns an
Attachmentobject given its name. attachments-
Returns all the attachments as
Attachmentobjects.
Once you have an Attachment object, you can access its name, MIME type and content length.
The accessors for the content vary by platform: on iOS it’s available as an NSData object or as an NSURL pointing to a read-only file;
in Java you read the data from an InputStream.
// Load an JPEG attachment from a document:
var doc = database.GetDocument("Robin");
var rev = doc.CurrentRevision;
var att = rev.GetAttachment("photo.jpg");
if (att != null)
{
var imageData = att.Content.ToList<byte>();
// Convert the raw image data into an Image object based
// on your development platform.
}Writing (and deleting) attachments
To create an attachment, first create a mutable UnsavedRevision object by calling createRevision on the document’s currentRevision.
Then call setAttachment on the new revision to add an attachment.
(You can of course also change the JSON by modifying the revision’s properties.)
Finally you call save to save the new revision.
Updating an attachment’s content (or type) works exactly the same way: the setAttachment method will replace any existing attachment with the same name.
// Add or update an image to a document as a JPEG attachment:
var doc = database.GetDocument("Robin");
var newRev = doc.CurrentRevision.CreateRevision();
var imageStream = GetAsset("photo.png");
newRev.SetAttachment("photo.jpg", "image/jpeg", imageStream);
var savedRev = newRev.Save();
Debug.Assert(savedRev != null);To delete an attachment, just call removeAttachment instead of setAttachment.
// Remove an attachment from a document:
var doc = database.GetDocument("Robin");
var newRev = doc.CurrentRevision.CreateRevision();
newRev.RemoveAttachment("photo.jpg");
var savedRev = newRev.Save();
Debug.Assert(savedRev != null);Attachment storage
In general, you don’t need to think about where and how Couchbase Lite is storing data. But since attachments can occupy a lot of space, it can be helpful to know where that space is and how it’s managed.
Attachments aren’t stored in the database file itself. Instead they are individual files, contained in a directory right next to the database file. Each attachment file has a cryptic name that is actually a SHA-1 digest of its contents.
As a consequence of the naming scheme, attachments are de-duplicated. If multiple attachments in the same database have exactly the same contents, the data is only stored once in the filesystem.
Updating a document’s attachment does not immediately remove the old version of the attachment. And deleting a document does not immediately delete its attachments. An attachment file has to remain on disk as long as there are any document revisions that reference it, And a revision persists until the next database compaction after it’s been replaced or deleted. (Orphaned attachment files are deleted from disk as part of the compaction process.) So if you’re concerned about the space taken up by attachments, you should compact the database frequently, or at least after making changes to large attachments.
View
A View is a persistent index of documents in a database, which you then query to find data. Couchbase Lite doesn’t have a query language like SQL. Instead, it uses a technique called map/reduce to generate indexes (views) according to arbitrary app-defined criteria. Queries can then look up a range of rows from a view, and either use the rows' keys and values directly or get the documents they came from.
The main component of a view (other than its name) is its map function. This function is written in the same language as your app—most likely Objective-C or Java—so it’s very flexible. It takes a document’s JSON as input, and emits (outputs) any number of key/value pairs to be indexed. The view generates a complete index by calling the map function on every document in the database, and adding each emitted key/value pair to the index, sorted by key. For example, a map function might grind through an address-book database and produce a set of mappings from names to phone numbers. The resulting index is persistent, and updated incrementally as documents change. (It’s very much like the type of index a SQL database creates internally to optimize queries.)
A view may also have a reduce function. If present, it can be used during queries to combine multiple rows into one. It can be used to compute aggregate values like totals or averages, or to group rows by common criteria (like collecting all the artists in a record collection). We’ll explain reduce functions later on.
| A view is not a query, it’s an index. Views are persistent, and need to be updated (incrementally) whenever documents change, so having large numbers of them can be expensive. Instead, it’s better to have a smaller number of views that can be queried in interesting ways. |
Creating and initializing views
View objects belong to a Database.
You create or find a view by calling the database’s viewNamed method, which will create and return a new View if none exists by that name.
Even though a view is persistent, its map and reduce functions aren’t. They’re just function pointers (or blocks, or inner classes) and have to be registered at runtime, before the view is queried. It’s good practice to set up views when your app starts up, right after opening the database:
// Create a view and register its map function:
var view = database.GetView("phones");
view.SetMap((doc, emit) =>
{
var phones = doc["phones"].AsList<string>();
foreach(var phone in phones)
{
emit(phone, doc["name"]);
}
}, "2");The version parameter to setMapBlock takes a bit of explanation.
During development, and as you update the app, you may change the behavior of a map function.
This invalidates any existing index generated by that function, so the next time the app runs, the view should rebuild the index from scratch using the new function.
Unfortunately the view indexer can’t tell that the map function has changed because it can’t see it’s source code!
Instead, you have to provide a version string that the indexer can compare, and you must change that string whenever you change the function.
The easiest thing to remember is just to set the version to "1" initially, and then increment it every time you edit any source code in the map function (or any function of yours that it calls).
Querying views
You query a view by using a Query object that you create from a View by calling createQuery.
This is a big topic, and is covered in a separate article on the Query class.
Map functions
Understanding map functions
As discussed in the introduction, a map function’s job is to look at a document’s JSON contents and from them produce (emit) zero or more key/value pairs to be indexed.
If you know SQL, you can think of it as corresponding to the expressions that immediately follow the SELECT and WHERE keywords, only more powerful because you have the full power of a programming language available.
For discussion purposes, here’s a simple map function in JavaScript:
function(doc) {
if (doc["type"] == "person")
emit(doc["name"], doc["phone"]);
}This function works with a database that contains, among other things, documents representing people, which are tagged with a type property whose value is “person”.
(This use of a type property is a common idiom.)
Every person document contains name and phone properties.
The map function simply checks whether the document represents a person, and if it does, it calls emit to add the name and phone number to the index.
The resulting index maps names to phone numbers. You can query it to look up someone by name and find their phone number. You can also query it to get ranges of names, in alphabetical order, which is very useful for driving GUI list views.
Rules for the map function
The map function is called by the indexer to help generate an index, and it has to meet certain requirements, otherwise the index won’t be consistent. It’s important to understand some rules so you can create a proper map function, otherwise your queries can misbehave in strange ways.
- It must be a "https://en.wikipedia.org/wiki/Pure_function[pure]" function
-
That means any time it’s called with the same input, it must produce exactly the same output. In other words, it can’t use any external state, just its input JSON.
- It can’t have side effects
-
It shouldn’t change any external state, because it’s unpredictable when it’s called or how often it’s called or in what order documents are passed to it.
- It must be thread-safe
-
It may be called on a background thread belonging to the indexer, or even in parallel on several threads at once.
In particular, avoid these common mistakes:
-
Don’t do anything that depends on the current date and time — that breaks the first rule, since your function’s output can change depending on the date/time it’s called. Common mistakes include emitting the current time as a timestamp, emitting a person’s age, or emitting only documents that have been modified in the past week.
-
Don’t try to "parameterize" the map function by referring to an external variable whose value you change when querying. It won’t work. People sometimes try this because they want to find various subsets of the data, like all the items of a particular color. Instead, emit all the values of that property, and use a key range in the query to pick out the rows with the specific value you want.
-
Don’t make any assumptions about when the map function is called. That’s an implementation detail of the indexer. (For example, it’s not called every time a document changes.)
-
Avoid having the map function call out into complex external code. That code might change later on to be stateful or have side effects, breaking your map function.
Keys and values
Both the key and value passed to emit can be any JSON-compatible objects: not just strings, but also numbers, booleans, arrays, dictionaries/maps, and the special JSON null object (which is distinct from a null/nil pointer).
In addition, the value emitted, but not the key, can be a null/nil pointer.
(It’s pretty common to not need a value in a view, in which case it’s more efficient to not emit one.)
Keys are commonly strings, but it turns out that arrays are a very useful type of key as well. This is because of the way arrays are sorted: given two array keys, the first items are compared first, then if those match the second items are compared, and so on. That means that you can use array keys to establish multiple levels of sorting. If the map function emits keys of the form [lastname, firstname], then the index will be sorted by last name, and entries with the same last name will be sorted by first name, just as if you’d used ORDER BY lastname, firstname in SQL.
Here are the exact rules for sorting (collation) of keys. The most significant factor is the key’s object type; keys of one type always sort before or after keys of a different type. This list gives the types in order, and states how objects of that type are compared:
-
null
-
false, true (in that order)
-
Numbers, in numeric order of course
-
Strings, case-insensitive. The exact ordering is specified by the Unicode Collation Algorithm. This is not the same as ASCII ordering, so the results might surprise you — for example, all symbols, including "~", sort before alphanumeric characters.
-
Arrays, compared item-by-item as described above.
-
Maps/dictionaries, also compared item-by-item. Unfortunately the order of items is ambiguous (since JSON doesn’t specify any ordering of keys, and most implementations use hash tables which randomize the order) so using these as keys isn’t recommended.
The source document, and redirection
In addition to its key and value, every index row also remembers the ID of the document that emitted it.
This can be accessed at query time via the QueryRow.documentID property, or more commonly via the shortcut QueryRow.document which uses the ID to load the Document object.
It can sometimes be useful to redirect this reference, i.e., to make the index row point to a different document instead.
You do this by emitting a value that’s a dictionary with a key _id whose value is the document ID you want the row to reference.
The QueryRow.documentID and accessors will then use this document ID instead.
No code example is currently available.Even if you’ve used the redirect technique, at query time you can still recover the ID of the actual document that emitted the row, by using the QueryRow.sourceDocumentID property.
Reduce functions
Understanding reduce functions
Reduce functions are the other half of the map/reduce technique.
They’re optional, and less commonly used.
A reduce function post-processes the indexed key/value pairs generated by the map function, by aggregating the values together.
Very commonly it counts them, or (if the values are numeric) totals or averages them.
The reduce function boils down data the way a chef reduces a sauce.
Or if you’re a SQL user, reduce functions are like SQL aggregation operators like COUNT or AVERAGE (only you get to define your own).
In general, most views don’t need reduce functions, so don’t feel like you’re missing something if you haven’t written one. But if you find yourself writing a query and counting the returned rows or adding up their values, you could do that more efficiently with a reduce function.
A reduce function takes an ordered list of key/value pairs, aggregates them together into a single object, and returns that object. Here’s an example, building on the phone-numbers example up above:
// Create a view and register its map and reduce functions:
var view = database.GetView("phones");
view.SetMapReduce((doc, emit) =>
{
var phones = doc["phones"].AsList<string>();
foreach(var phone in phones)
{
emit(phone, doc["name"]);
}
}, (keys, values, rereduce) => values.ToList().Count, "2.0");For efficiency, the key/value pairs are passed in as two parallel arrays. This reduce block just counts the number of values and returns that number as an object. We could query this view, with reduce enabled, and get the total number of phone numbers in the database. Or by specifying a key range we could find the number of phone numbers in that range, for example the number in a single area code.
Here’s just the body of a reduce function that totals up numbers. (This function would belong in a different view, whose map function emitted numeric values.)
var total = 0.0;
foreach(var value in values.ToList())
{
total += Convert.ToDouble(value);
}
return total;This totaling is common enough that CBLView provide a utility to do it for you, the totalValues method.
Rereducing
The previous section ignored the boolean rereduce parameter that’s passed to the reduce function.
What’s it for?
Unfortunately, from your perspective as a reduce-function-writer it’s just there to make your job a bit harder.
The reason it exists is because it’s part of a major optimization that makes reducing more efficient for the query engine.
Think of a view with a hundred million rows in its index. To run a reduced query against the whole index (with no startKey or endKey) the database will have to read all hundred million keys and values into memory at once, so it can pass them all to your reduce function. That’s a lot of overhead, and on a mobile device it’s likely to crash your app.
Instead, the database will read the rows in chunks.
It’ll read some number of rows into memory, send them to your reduce function, release them from memory, then go on to the next rows.
This scales very well, but now there’s the problem of what to do with the multiple reduced values returned by your function.
Reducing is supposed to produce one end result, not several! The answer is to reduce the list of reduced values — to re-reduce.
The rereduce parameter is there to tell your reduce function that it’s being called in this special re-reduce mode.
When re-reducing there are no keys, and the values are the ones already returned by previous runs of the same reduce function. The function’s job is, once again, to combine the values into a single value and return it.
Sometimes you can handle re-reduce mode exactly like reduce mode.
The second reduce block shown above (the one that totals up the values) can do this.
Since its input values are numbers, and its output is a number, the re-reduce is done the same way as the reduce, and it can just ignore the rereduce flag.
But sometimes re-reduce has to work differently, because the output of the reduce stage doesn’t look like the indexed values. The first reduce example — the one that just counts the rows — is an example. To re-reduce a list of row counts, you can’t just count them, you have to add them. Let’s revisit that example and add proper support for re-reducing:
// Create a view and register its map and reduce functions:
let phoneView = database.GetView("phones");
phoneView.SetMapReduce((doc, emit) =>
{
var phones = doc["phones"].AsList<string>();
foreach(var phone in phones)
{
emit(phone, doc["name"]);
}
}, (keys, values, rereduce) => {
if (rereduce)
{
return View.TotalValues(values.ToList());
}
else
{
return values.ToList().Count;
}
}, "2.0");When the rereduce flag is off, this just counts the raw values as before.
But when the flag is on, it knows it’s been given an array of row counts, so it invokes the totalValues method to add them up.
Now that you know how re-reduce works, we should let you know that Couchbase Lite 1.0 doesn’t actually use re-reduce — your reduce function will always be given index rows, never already-reduced values.
The rereduce parameter is in the API for future expansion, because in the future Couchbase Lite will use it.
For now, it’s up to you whether you want to ignore re-reduce (and maybe find that your reduce function breaks in the future) or code defensively and implement it now even though it isn’t used yet.
Rules for the reduce function
The reduce function has the same restrictions as the map function (see above): It must be a "pure" function that always produce the same output given the same input. It must not have side effects. And it must be thread-safe. In addition:
-
Its output should be no larger than its input. Usually this comes naturally. But it is legal to return an array or dictionary, and sometimes people have tried to make reduce functions that transform the input values without actually making them any smaller. The problem with this is that it scales badly, and as the size of the index grows, the indexer will eventually run out of memory and fail.
Development considerations
Map function design
When to emit a whole document as the value?
In some places you’ll see code that does something like emit(key, doc) , i.e., emitting the document’s entire body as the value.
(Some people seem to do this by reflex whenever they don’t have a specific value in mind.)
It’s not necessarily bad, but most of the time you shouldn’t do it.
The benefit is that, by having the document’s properties right at hand when you process a query row, it can make querying a little bit faster (saving a trip to the database to load the document).
But the downside is that it makes the view index a lot larger, which can make querying slower.
So whether it’s a net gain or loss depends on the specific use case.
We recommend that you just set the value to null if you don’t need to emit any specific value.
Is it OK is the same key is emitted more than once? The index allows duplicate keys, whether emitted by the same document or different documents. A query will return all of those key/value pairs if they match. They’ll be sorted by the ID of the document that was responsible for emitting them; if a doc emits the same key multiple times, the order is undefined.
When is the map function called? View indexes are updated on demand when queried. So after a document changes, the next query made to a view will cause that view’s map function to be called on the doc’s new contents, updating the view index. (But remember that you shouldn’t write any code that makes assumptions about when map functions are called.)
If a document has conflicts, which conflicting revision gets indexed?
The document’s currentRevision, sometimes called the "winning" revision, is the one that you see in the API if you don’t request a revision by ID.
Performance
How to improve your view indexing: The main thing you have control over is the performance of your map function, both how long it takes to run and how many objects it allocates. Try profiling your app while the view is indexing and see if a lot of time is spent in the map function; if so, optimize it. See if you can short-circuit the map function and give up early if the document isn’t a type that will produce any rows. Also see if you could emit less data. (If you’re emitting the entire document as a value, don’t.)
Query
A query is the action of looking up results from a view’s index.
In Couchbase Lite, queries are objects of the Query class.
To perform a query you create one of these, customize its properties (such as the key range or the maximum number of rows) and then run it.
The result is a QueryEnumerator, which provides a list of QueryRow objects, each one describing one row from the view’s index.
There’s also a special type of query called an all-docs query. This type of query isn’t associated with any view; or rather, you can think of it as querying an imaginary view that contains one row for every document in the database. You use an all-docs query to find all the documents in the database, or the documents with keys in a specific range, or even the documents with a specific set of keys. It can also be used to find documents with conflicts.
Couchbase Lite also provides live queries. Once created, a live query remains active and monitors changes to the view’s index, notifying observers whenever the query results change. Live queries are very useful for driving UI components like table views.
Creating and configuring queries
Query objects are created by a View's `createQuery method, and by a Database's `createAllDocumentsQuery method.
In its default state a Query object will return every row of the index, in increasing order by key.
But there are several properties you can configure to change this, before you run the query.
Here are the most basic and common ones:
startKey-
The key to start at. The default value,
null, means to start from the beginning. endKey-
The last key to return. The default value,
null, means to continue to the end. descending-
If set to
true, the keys will be returned in reverse order. (This also reverses the meanings of thestartKeyandendKeyproperties, since the query will now start at the highest keys and end at lower ones!) limit-
If nonzero, this is the maximum number of rows that will be returned.
skip-
If nonzero, this many rows will be skipped (starting from the
startKeyif any).
Some more advanced properties that aren’t used as often:
keys-
If provided, the query will fetch only the rows with the given keys (and
startKeyandendKeywill be ignored). startKeyDocID-
If multiple index rows match the startKey, this property specifies that the result should start from the one(s) emitted by the document with this ID, if any. (Useful if the view contains multiple identical keys, making .startKey ambiguous.)
endKeyDocID-
If multiple index rows match the endKey, this property specifies that the result should end with from the one(s) emitted by the document with this ID, if any. (Useful if the view contains multiple identical keys, making .startKey ambiguous.)
indexUpdateMode-
Changes the behavior of index updating. By default the index will be updated if necessary before the query runs. You can choose to skip this (and get possibly-stale results), with the option of also starting an asynchronous background update of the index.
prefixMatchLevel-
If nonzero, enables prefix matching of string or array keys.
-
A value of 1 treats the endKey itself as a prefix: if it’s a string, keys in the index that come after the endKey, but begin with the same prefix, will be matched. (For example, if the endKey is
"foo"then the key"foolish"in the index will be matched, but not"fong".) Or if the endKey is an array, any array beginning with those elements will be matched. (For example, if the endKey is[1], then[1, "x"]will match, but not[2].) If the key is any other type, there is no effect. -
A value of 2 assumes the endKey is an array and treats its final item as a prefix, using the rules above. (For example, an endKey of
[1, "x"]will match[1, "xtc"]but not[1, "y"].) -
A value of 3 assumes the key is an array of arrays, etc.
Note that if the
.descendingproperty is also set, the search order is reversed and the above discussion applies to thestartKey, not theendKey. -
There are other advanced properties that only apply to reducing and grouping:
mapOnly-
If set to true, prevents the reduce function from being run, so you get all of the index rows instead of an aggregate. Has no effect if the view has no reduce function.
groupLevel-
If greater than zero, enables grouping of rows. The value specifies the number of items in the value array that will be grouped.
// Set up a query for a view that indexes blog posts, to get the latest:
var query = database.GetView("postsByDate").CreateQuery();
query.Descending = true;
query.Limit = 20;All-documents queries
An all-docs query isn’t associated with a view;
or rather, you can think of it as querying an imaginary view that contains one row for every document in the database, whose key is the document ID.
It supports all the standard view options, so you can query ranges of document IDs, reverse the order, and even query a specific set of documents using the keys property.
All-docs queries also have a special property called allDocsMode that can customize their behavior.
Its values are:
allDocs-
The default mode. Returns all non-deleted documents.
includeDeleted-
In this mode, deleted documents are included as well.
showConflicts-
In this mode, each
QueryRow's `conflictingRevisionsproperty can be used to find whether it’s in conflict and what the IDs of the conflicting revisions are. onlyConflicts-
Like
showConflicts, but only conflicted documents are returned.
(These are not flags. You can only choose one.)
// Let's find the documents that have conflicts so we can resolve them:
var query = database.CreateAllDocumentsQuery();
query.AllDocsMode = AllDocsMode.OnlyConflicts;
var rows = query.Run();
foreach (var row in rows)
{
if (row.GetConflictingRevisions().Any())
{
Log.W(Tag, "Conflict in document: " + row.DocumentId);
BeginConflictResolution(row.Document);
}
}Running queries
After a Query object is set up just right, you call its run method to get the results.
These are returned as a QueryEnumerator object, which mainly serves as an enumerable collection of QueryRow objects.
Each QueryRow has two main properties, its key and its value.
These are what were emitted to the index.
(Or in the case of an all-docs query, the key is the same as the document ID.)
It also has a documentID property that identifies the document that the key and value were emitted from, although usually you’d access the document property instead, which gives you the Document object directly.
// Let's query a view that maps product names to prices,
// starting with the "M"s and showing 100 widgets:
var query = database.GetView("widgetsByName").CreateQuery();
query.StartKey = "m";
query.Limit = 100;
var rows = query.Run();
foreach (var row in rows)
{
var name = row.Key;
var cost = Convert.ToDouble(row.Value);
Log.W(Tag, "Widget named " + name + " costs $" + cost);
}Re-running queries, and LiveQuery
It’s OK to run the same Query again. You can even change its settings before the next run. But if you find yourself wanting to re-run a query over and over to check for updates, there are some optimizations to consider.
First, there’s a quick check to see whether the previous query results are still up to date.
If you keep the QueryEnumerator object and check its stale property, a false value means that the view index hasn’t changed and re-running the query won’t give you a different result set.
Second, even if the enumerator says it’s stale and you re-run the query, the new results might not be any different.
The stale method is conservative and might report false positives, and even if the index did change, your query might not include any of the changed rows.
You can quickly check if the new QueryEnumerator you got is equivalent to the old one by comparing the objects for equality (e.g., using equals in Java, or -isEqual: in Objective-C).
// Check whether the query result set has changed:
if (queryResult == null || queryResult.Stale)
{
QueryEnumerator newResult = query.Run();
if (!queryResult.Equals(newResult))
{
queryResult = newResult;
UpdateMyUserInterface();
}
}There’s a class that actually does this work for you, called LiveQuery.
A live query stays active and monitors the database and view index for changes.
When there’s a change it re-runs itself automatically, and if the query results changed it notifies any observers.
LiveQuery is a great way to build reactive user interfaces, especially table/list views, that keep themselves up to date.
For example, as the replicator runs and pulls new data from the server, a LiveQuery-driven UI will automatically update to show the data without the user having to manually refresh.
This helps your app feel quick and responsive.
private void InitializeQuery()
{
// Set up my live query during view initialization:
var query = database.GetView("widgets").CreateQuery();
query.Limit = 100;
liveQuery = query.ToLiveQuery();
liveQuery.Changed += (sender, e) => DisplayRows(e.Rows);
liveQuery.Start();
}Querying key ranges
There are some subtleties to working with key ranges (startKey and endKey).
The first is that if you reverse the order of keys, by setting the reverse property, then the startKey needs to be greater than the endKey.
That’s the reason they’re named start and end, rather than min and max.
In the following example, note that the key range starts at 100 and ends at 90;
if we’d done it the other way around, we’d have gotten an empty result set.
// Set up a query for the highest-rated movies:
var query = database.GetView("postsByDate").CreateQuery();
query.Descending = true;
query.StartKey = 100;
query.EndKey = 90;Second is the handling of compound (array) keys.
When a view’s keys are arrays, it’s very common to want to query all the rows that have a specific value (or value range) for the first element.
The start key is just a one-element array with that value in it, but it’s not obvious what the end key should be.
What works is an array that’s like the starting key but with a second object appended that’s greater than any possible value.
For example, if the start key is (in JSON) ["red"] then the end key could be ["red", "ZZZZ"] …because none of the possible second items could be greater than "ZZZZ", right?
Unfortunately this has obvious problems.
The correct stop value to use turns out to be an empty object/dictionary, {}, making the end key ["red", {}].
This works because the sort order in views puts dictionaries last.
// Assume the view's keys are like [color, model]. We want all the red ones.
var query = database.GetView("carsByColorAndModel").CreateQuery();
query.StartKey = new List<object> {"red"};
query.EndKey = new List<object> {"red", new Dictionary<string, object>()};Reducing
If the view has a reduce function, it will be run by default when you query the view. This means that all rows of the output will be aggregated into a single row with no key, whose value is the output of the reduce function. (See the View documentation for a full description of what reduce functions do.)
(It’s important to realize that the reduce function runs on the rows that would be output, not all the rows in the view.
So if you set the startKey and/or endKey, the reduce function runs only on the rows in that key range.)
If you don’t want the reduce function to be used, set the query’s mapOnly property to true.
This gives you the flexibility to use a single view for both detailed results and statistics.
For example, adding a typical row-count reduce function to a view lets you get the full results (with mapOnly=true) or just the number of rows (with mapOnly=false).
// This view's keys are order dates, and values are prices.
// The reduce function computes an average of the input values.
var query = database.GetView("ordersByDateView").CreateQuery();
query.StartKey = "2014-01-01";
query.EndKey = "2014-02-01";
query.InclusiveEnd = false;
// First run without reduce to get the individual orders for January '14:
query.MapOnly = true;
var rows = query.Run();
foreach (var row in rows)
{
var date = row.Key;
var price = Convert.ToDouble(row.Value);
Log.D(Tag, String.Format("On {0}: order for ${1:0.##}", date, price));
}
// Now run with reduce to get the average order price for January '14:
query.MapOnly = false;
rows = query.Run();
Debug.Assert(rows.Count > 0);
var avg = Convert.ToDouble(rows.GetRow(0).Value);
Log.D(Tag, String.Format("Average order was ${0:0.##}", avg));Grouping by key
The groupLevel property of a query allows you to collapse together (aggregate) rows with the same keys or key prefixes.
And you can compute aggregated statistics of the grouped-together rows by using a reduce function.
One very powerful use of grouping is to take a view whose keys are arrays representing a hierarchy — like [genre, artist, album, track] for a music library — and query a single level of the hierarchy for use in a navigation UI.
In general, groupLevel requires that the keys be arrays;
rows with other types of keys will be ignored.
When the groupLevel is n, the query combines rows that have equal values in the first n items of the key into a single row whose key is the n-item common prefix.
groupLevel=1 is slightly different in that it supports non-array keys: it compares them for equality.
In other words, if a view’s keys are strings or numbers, a query with groupLevel=1 will return a row for each unique key in the index.
We’ve talked about the keys of grouped query rows, but what are the values?
The value property of each row will be the result of running the view’s reduce function over all the rows that were aggregated;
or if the view has no reduce function, there’s no value.
(See the View documentation for information on reduce functions.)
Here’s an interesting example.
We have a database of the user’s music library, and a view containing a row for every audio track, with key of the form [genre, artist, album, trackname] and value being the track’s duration in seconds.
The view has a reduce function that simply totals the input values.
The user’s drilled down into the genre "Mope-Rock", then artist "Radiohead", and now we want to display the albums by this artist, showing each album’s running time.
var query = database.GetView("hierarchyView").CreateQuery();
query.GroupLevel = 3;
query.StartKey = new List<object> {"Mope-Rock", "Radiohead"};
query.EndKey = new List<object> {"Mope-Rock", "Radiohead", new Dictionary<string, object>()};
// GroupLevel = 3 will return [genre, artist, album] keys.
var albumTitles = new List<string>();
var albumTimes = new List<string>();
var rows = query.Run();
foreach (var row in rows)
{
var keys = row.Key.AsList<string>();
albumTitles.Add(keys[2]); // title is 3rd item of key
albumTimes.Add((string)row.Value); // value is album's running time
}Replication
A Replication object represents a replication (or "sync") task that transfers changes between a local database and a remote one. To replicate, you first get a new Replication object from a Database, then configure its settings, then tell it to start. The actual replication runs asynchronously on a background thread; you can monitor its progress by observing notifications posted by the Replication object when its state changes, as well as notifications posted by the database when documents are changed by the replicator.
A typical application will create a pair of replications (push and pull) at launch time, both pointing to the URL of a server run by the application vendor. These stay active continuously during the lifespan of the app, uploading and downloading documents as changes occur and when the network is available.
(Of course, atypical applications can use replication differently. The architecture is very flexible, supporting one-way replication, peer-to-peer replication, and replication between multiple devices and servers in arbitrary directed graphs. An app might also choose to replicate only once in a while, or only with a subset of its documents.)
The application code doesn’t have to pay attention to the details: it just knows that when it makes changes to the local database they will eventually be uploaded to the server, and when changes occur on the server they will eventually be downloaded to the local database. The app’s job is to make the UI reflect what’s in the local database, and to reflect user actions by making changes to local documents. If it does that, replication will Just Work without much extra effort.
Types of replications
- Push vs Pull
-
A push replication uploads changes from the local database to the remote one; a pull downloads changes from the remote database to the local one.
- One-shot vs Continuous
-
By default a replication runs long enough to transfer all the changes from the source to the target database, then quits. A continuous replication, on the other hand, will stay active indefinitely, watching for further changes to occur and transferring them.
- Filtered
-
Replications can have filters that restrict what documents they’ll transfer. This can be useful to limit the amount of a large remote database that’s downloaded to a device, or to keep some local documents private. A special type of filter used with the Couchbase Sync Gateway is the set of channels that a pull replication will download from. It’s also possible to limit a replication to an explicit set of document IDs.
Creating replications
You create a Replication object by calling the Database methods createPullReplication or createPushReplication.
Both of these take a single parameter, the URL of the remote database to sync with.
As the names imply, each method creates a replication that transfers changes in one direction only;
if you want bidirectional sync, as most apps do, you should create one of each.
Next you can customize the replication settings.
The most common change is to set the continuous property to true.
You may also need to supply authentication credentials, like a username/password or a Facebook token.
var url = new Uri("https://example.com/mydatabase/");
var push = database.CreatePushReplication(url);
var pull = database.CreatePullReplication(url);
var auth = AuthenticatorFactory.CreateBasicAuthenticator(username, password);
push.Authenticator = auth;
pull.Authenticator = auth;
push.Continuous = true;
pull.Continuous = true;You will also probably want to monitor the replication’s progress, particularly because this will tell you if errors occur, but also if you want to display a progress indicator to the user. The API for registering as an observer is platform-specific.
Once everything is set, you call start to start the replication.
If the replication is continuous, it’ll keep running indefinitely.
Otherwise, the replication will eventually stop when it’s transferred everything.
push.Changed += (sender, e) =>
{
// Will be called when the push replication status changes
};
pull.Changed += (sender, e) =>
{
// Will be called when the pull replication status changes
};
push.Start();
pull.Start();
this.push = push;
this.pull = pull;Filtered replications
You can restrict a replication to only a subset of the available documents, by writing a filter function. There are several types of filtered replication, based on the direction and the type of server.
Filtered push replications
During a push replication, the candidate documents live in your local database, so the filter function runs locally.
You define it as a native function (a block in Objective-C, an inner class method in Java), assign it a name, and register it with the Database object.
You then set the filter’s name as the filter property of the Replication object.
The replicator passes your filter function a SavedRevision object. The function can examine the document’s ID and properties, and simply returns true to allow the document to be replicated, or false to prevent it from being replicated.
| The filter function will be called on the replicator’s background thread, so it should be thread-safe. Ideally it shouldn’t reference any external state, but this isn’t strictly required. |
The filter function can also be given parameters.
The parameter values are specified in the Replication.filterParams property as a dictionary/map, and passed to the filter function.
This way you can write a generalized filter that can be used with different replications, and also avoid referencing external state from within the function.
For example, a function could filter documents created in any year, accepting the specific year as a parameter.
// Define a filter that matches only docs with a given "owner" property.
// The value to match is given as a parameter named "name":
database.SetFilter("byOwner", (revision, filterParams) =>
{
var nameParam = filterParams["name"];
var owner = (string)revision.GetProperty("owner");
return (nameParam != null) && nameParam.Equals(owner);
});
// Set up a filtered push replication using the above filter block,
// that will push only docs whose "owner" property equals "Waldo":
var push = database.CreatePushReplication(url);
push.Filter = "byOwner";
push.FilterParams = new Dictionary<string, object> { {"name", "Waldo"} };Filtered pull from Sync Gateway
Channels are used to filter documents being pulled from the Sync Gateway. Every document stored in a Sync Gateway database is tagged with a set of named channels by the Gateway’s app-defined sync function. Every pull replication from the Gateway is already implicitly filtered by the set of channels that the user’s account is allowed to access; you can filter it further by creating an array of channel names and setting it as the value of the channels property of a pull Replication. Only documents tagged with those channels will be downloaded.
No code example is currently available.
Replication properties changed after it has already started won’t have any effect.
If you wish to change replication properties such as channels, authentication, etc, you must create a new replication object using the createPushReplication or createPullReplication method.
|
Filtered pull from CouchDB, PouchDB or Cloudant
Since Couchbase Lite 1.2, filter functions in pull replications with non-Couchbase databases are no longer available.
There is an incompatibility in the way the filter parameter is handled in the POST /{db}/_changes request (see #1139).
Filtering by document IDs
In one-shot pull replications with Sync Gateway, it’s possible to specify a list of document IDs (this feature is not available for replications in continuous mode, see #1703). The code below pulls the documents with ID "123" and "xyz" if they exist and the user has access to them.
var pull = database.CreatePullReplication(SyncGatewayUrl);
pull.DocIds = new string[] {"123", "xyz"};
pull.Start();For push replications with Sync Gateway, this functionality is available in one-shot and continuous replications.
Observing and monitoring replications
Since a replication runs asynchronously, if you want to know when it completes or when it gets an error, you’ll need to register as an observer to get notifications from it. The details of this are platform-specific.
A replication has a number of properties that you can access, especially from a notification callback, to check on its status and progress:
-
status: An enumeration that gives the current state of the replication. The values are Stopped, Offline, Idle and Active.-
Stopped: A one-shot replication goes into this state after all documents have been transferred or a fatal error occurs. (Continuous replications never stop.)
-
Offline: The remote server is not reachable. Most often this happens because there’s no network connection, but it can also occur if the server’s inside an intranet or home network but the device isn’t. (The replication will monitor the network state and will try to connect when the server becomes reachable.)
-
Idle: Indicates that a continuous replication has "caught up" and transferred all documents, but is monitoring the source database for future changes.
-
Active: The replication is actively working, either transferring documents or determining what needs to be transferred.
-
-
lastError: The last error encountered by the replicator. (Not all errors are fatal, and a continuous replication will keep running even after a fatal error, by waiting and retrying later.) -
completedChangesCount,changesCount: The number of documents that have been transferred so far, and the estimated total number to transfer in order to catch up. The ratio of these can be used to display a progress meter. Just be aware that changesCount may be zero if the number of documents to transfer isn’t known yet, and in a continuous replication both values will reset to zero when the status goes from Idle back to Active.
// The replication reporting the notification is either
// the push or the pull, but we want to look at the
// aggregate of both the push and pull.
// First check whether replication is currently active:
var active = push.Status == ReplicationStatus.Active ||
pull.Status == ReplicationStatus.Active;
if (!active)
{
DismissProgressBar();
}
else
{
var total = push.CompletedChangesCount + pull.CompletedChangesCount;
var progress = push.ChangesCount + pull.ChangesCount;
ShowProgressBar(progress, total);
}Detecting unauthorized credentials
The replication listener can also be used to detect when credentials are incorrect or access to Sync Gateway requires authentication.
...
pull.Changed += Changed;
push.Changed += Changed;
}
void Changed(object sender, ReplicationChangeEventArgs e)
{
if (pull.Status == ReplicationStatus.Active || push.Status == ReplicationStatus.Active)
{
Console.WriteLine("Sync in progress");
}
else if (e.LastError != null)
{
Exception error = e.LastError;
if (error is HttpResponseException)
{
HttpResponseException exception = (HttpResponseException)error;
if ((int) exception.StatusCode == 401)
{
Console.WriteLine("Authentication error");
}
}
}
}Data Modeling
If you’re familiar with data modeling for relational databases, you’ll notice differences in the way it is done for Couchbase Lite.
Couchbase Lite is a document database. Unlike traditional relational databases, data is stored in documents rather than in table rows. A document is a JSON object containing a number of key-value pairs. Entities, and relationships between entities, are managed within the document itself.
The Basics
A starting point for data modeling in Couchbase Lite is to look at a denormalized entity stored in a single document. Consider modeling a contact record stored in a relational database in a CONTACTS table, of the form:
| ID | FIRST_NAME | LAST_NAME | |
|---|---|---|---|
100 |
John |
Smith |
john.smith@couchbase.com |
The equivalent representation in JSON document form would be something like:
{
"id": "contact100",
"type": "contact",
"first_name":"John",
"last_name ":"Smith",
"email": "john.smith@couchbase.com"
}Functionally related properties can be grouped using an embedded document. If we wanted to store address information for our contact, it could be modeled as:
{
"id": "contact100",
"type": "contact",
"first_name": "John",
"last_name ": "Smith",
"email": "john.smith@couchbase.com",
"address": {
"address_line": "123 Main Street",
"city": "Mountain View",
"country": "US"
}
}One-to-Many Relationships
Things get interesting when the contact record has more than one related record that we want to model. There are two main options for modeling one-to-many relationships in a document database — as embedded documents, and as related documents.
Using Embedded Documents
When a contact can have more than one address, the addresses would commonly be stored in a relational database using a separate ADDRESSES table:
| ID | CONTACT_ID | ADDRESS_LINE | CITY | COUNTRY |
|---|---|---|---|---|
200 |
100 |
123 Main Street |
Mountain View |
US |
201 |
100 |
123 Market |
San Francisco |
US |
In a document database, the address information could instead be stored as an array of embedded documents within the contact document:
{
"id": "contact100",
"type": "contact",
"first_name": "John",
"last_name" : "Smith",
"email": "john.smith@couchbase.com",
"addresses": [
{
"address_line": "123 Main Street",
"city": "Mountain View",
"country": "US"
},
{
"address_line": "123 Market",
"city": "San Francisco",
"country": "US"
}
]
}The embedded document approach reduces the amount of work that your application needs to do in order to work with the Contact object — there is no additional query required to retrieve the embedded information.
Using Related Documents
There are scenarios where the embedded document approach isn’t ideal, including:
-
Large number of related entities. Embedding a large number of related entities results in a large document. This can result in slower document handling, as the entire document needs to be passed around when making updates.
-
Concurrency. When multiple users are working on a single document, there’s a higher risk of conflicts being introduced. Related documents can be used to isolate updates being made by different users.
The most common implementation for related documents is the belongsTo pattern. Consider the scenario where any user can assign a task to a contact, and a contact can end up with a large number of volatile task records. Here we define a new task document, which includes the contact key that the task record belongs to:
{
"id": "task300",
"type": "task",
"contact_id": "contact100"
"description": "Task details",
"status": "complete"
}Under this implementation, users can modify task records concurrently without introducing conflict scenarios for the related contact record. It can also support a large number of task records per contact without impacting the size of the related contact record.
Peer-to-Peer
Two instances of Couchbase Lite can directly sync with each other without a server (peer-to-peer). At least one of them must use the Couchbase Lite Listener library, which enables any Couchbase Lite database to become the remote in a replication by listening on a TCP port and by exposing the standard replication endpoints on that port.
It becomes an alternate entry-point into the data store. Another peer can therefore use the URL and port number in the replicator to sync data to and from the database currently listening.
Some typical Listener use cases include:
-
Synchronizing with selected peer devices on the same LAN network.
-
Offline/online: use peer-to-peer in conjunction with Sync Gateway.
Installing the Listener library
Refer to the Installation section to install the Listener component. The Couchbase Lite Listener is coupled to Couchbase Lite. Both frameworks should always have the same release version.
Configuring
To begin using the Listener you must create an instance by specifying a manager instance and port number.
Manager manager = Manager.SharedInstance;
listener = new CouchbaseLiteTcpListener (manager, 55000, CouchbaseLiteTcpOptions.AllowBasicAuth);
listener.SetPasswords(new Dictionary<string, string>() { { "hello", "pw123" } });
listener.Start ();Make sure to keep a reference to the listener instance in your application otherwise it may be garbage collected and unexpectedly stop listening for incoming HTTP requests. In the example above, the listener instance is initialized as an instance property of the class.
Basic authentication is the recommended approach for protecting database access on the LAN.
The listening peer can optionally be initialized with a list of username/password pairs.
The peer that intends to run the replication must provide the same username/password http://username:password@hostname:port/dbname.
Discovery
Once you have set up the Listener as an endpoint for other peers to replicate to or from, you can use different discovery methods to browse for peers and subscribe to those of interest.
This section covers two ways to discover peers:
-
Using a QR code to encode the peer’s remote URL.
-
DNS Service Discovery (DNS-SD, aka Bonjour).
QR code
PhotoDrop
PhotoDrop is a P2P sharing app similar to the iOS AirDrop feature that you can use to send photos across devices. The source code is available for iOS and Android. The QR code is used for advertising an adhoc endpoint URL that a sender can scan and send photos to.
DNS-SD
DNS Service Discovery is a standard for discovering services based on a service type. It’s usually coupled with Multicast DNS, which allows devices to broadcast their existence and services on a LAN without requiring a DNS server. These technologies are usually referred to as Bonjour, which is Apple’s name for its implementation, but they’re available under other names on most operating systems. Android calls them Network Service Discovery.
The first step to using Bonjour for peer discovery is to advertise a service with the following properties:
- Type
-
Bonjour can be used by many other types of devices on the LAN (printers, scanners, other apps etc.). The service type is a way to interact only with peers whose service type is the same.
- Name
-
A string to serve as identifier for other peers. It should be unique for each peer. It does not need to be human-readable.
- Port
-
The port number the Listener is running on.
- Metadata
-
Optional data that will be sent in the advertizment packets (the size limit is around 1.5KB).
To browse for peers on the network, each implementation has an asynchronous API to get notified as peers go online and offline from the network. Given this method of device discovery is platform specific, we recommend to follow the guides below. Once a peer device is discovered and the hostname is resolved, you can start a push and/or pull replication in the same way you would with Sync Gateway.
Resources
Useful resources to work with mDNS include:
- Bonjour for iOS and Mac applications
-
The Couchbase Lite SDK exposes part of the Bonjour API for an easier integration. The official documentation for iOS and Mac applications can be found in the NSNetService Programming Guide.
- NSD for Android applications
-
The de facto framework for Android is called Network Service Discovery (NSD) and is compatible with Bonjour since Android 4.1. The official guide can be found in the Android NSD guide.
- JmDNS
-
Implementation in Java that can be used in Android and Java applications (official repository).
Bonjour browsers
Bonjour browsers are useful to monitor devices broadcasting a particular service on the LAN (OS X Bonjour browser, iOS app, Windows browser)
Connecting
Once the IP address of another device is known you can start replicating data to or from that peer. However, there are some good practice guidelines to follow in order to replicate the changes as they are persisted to a particular node.
Filter functions
It may be desirable to use filter functions to replicate only the documents of interest to another peer. Filter functions in a peer-to-peer context are executed when the start method on the replication object is called. This is a major difference with the Sync Function available on Sync Gateway that builds the access rules when documents are saved to the Sync Gateway database.
Port allocation
If the port number passed to the Listener is hardcoded, there is a small chance that another application may already be using it. To avoid this scenario, specifying a value of 0 for the port in the Listener constructor will let the TCP stack pick a random available port.
Remote UUID
The replication algorithm keeps track of what was last synchronized with a particular remote database. To identify a remote, it stores a hash of the remote URL http://hostname:port/dbname and other properties such as filters, filter params etc. In the context of peer-to-peer, the IP address will frequently change which will result in a replication starting from scratch and sending over every single document although they may have already been replicated in the past. You can override the method of identifying a remote database using the remoteUUID property of the replicator. If specified, it will be used in place of the remote URL for calculating the remote checkpoint in the replication process.
Security
In addition to using basic authentication, it is also possible to enable SSL over peer-to-peer connections.
SSL for Peer-to-peer
var path = System.IO.Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.ApplicationData), "unit_test.pfx");
var cert = X509Manager.GetPersistentCertificate("127.0.0.1", "123abc", path);
CouchbaseLiteTcpListener listener = new CouchbaseLiteTcpListener(manager, 0, CouchbaseLiteTcpOptions.UseTLS, cert);The Listener is now serving SSL using an automatically generated identity.
Wait, Is This Secure?
Yes and no. It encrypts the connection, which is unquestionably much better than not using SSL. But unlike the usual SSL-in-a-browser approach you’re used to, it doesn’t identify the server/listener to the client. The client has to take the cert on faith the first time it connects.
Release Notes
Deprecation notices
The following features are being deprecated in Couchbase Mobile 1.4 and will be unsupported in 2.0.
-
ForestDB
-
Bonjour P2P Discovery Service
The following platforms are being deprecated in Couchbase Mobile 1.4 and will be unsupported in 2.0.
-
.NET 3.5
1.4.4 release
-
#937 Pull Sync throws Exception because of updating document with attachment on couchdb
-
#1019 Change default socket timeout to be slightly more than default heartbeat
-
#1023 GetPendingDocumentIDs() documents stuck in the queue in some situations
-
#1029 Unable to set document expiration longer than ~50 days in the future
-
#1055 Lack of thread safety in hashset causing odd exception
1.4.1 release
-
#778 Push sync becomes slower as local DB grows, fails to advance lastSequence
-
#821 .NET not encoding atts_since
-
#824 Pull replication stopping when coming online
-
#830 Remove RunInOuterTransaction
-
#832 New_edits on _bulk_docs should default to true
-
#834 1.4 breaks custom headers on PUT HTTP requests
-
#835 Unable to select multiple values with LINQ 1.4
-
#840 Couchbase.Lite.dll missing Product Version Info and Others
-
#847 Trying to remove encryption from a SQLite DB throws an exception
-
#848 Retry loop causes web socket changes feed to stop
-
#850 Wrong return code for listener causes problems with puller and deleted items.
-
#853 Updating a design doc view map function does not take effect
-
#863 PollInterval is not obeyed
-
#910 Channel removal potentially disrupts attachments
-
#914 Bulk download error not passed to client
1.4 release
-
An
isDeletionproperty is now available on theDatabaseChangeobject to identify if a change is tombstone document.
-
#245 Implement LINQ IQueryable
-
#575 Package Custom SQLite
-
#709 Implement LiteServ on mobile platforms
-
#741 Remove Mono.Security build
-
#745 Support 'stale=false' queries in Listener
-
#766 Push replication does not work when attachment content type is missing
-
#797 Add DatabaseChangedEventArgs.IsDeletion to public API
-
#802 Attempt to silence websockets when they shutdown
-
#672 .NET LiteServ is loading windows specific binaries on mac
-
#710 SQL Exception caused by trying to query non-existent
maps_#table -
#713 QueryOptions skip and limit used incorrectly during reduce
-
#718 V1.3 Continuous replication stops on change tracker error
-
#719 Replication - Inconsistent Number of Documents After Replicating
-
#724 V1.3 GetPendingDocumentIDs value is cached while offline for Push
-
#725 Replication fails to authenticate with POST _replicate cookie.
-
#727 BlobStoreWriter fails to delete encryption marker when removing encryption
-
#731 Missing docs when pushing to multiple sync gateways
-
#732 Transaction rollback does not invalidate cached doc ID map
-
#735 SIGSEGV when closing a database while replication is still active
-
#742 CB Lite on Android Xamarin fails to replicate when local DB is large
-
#749 Attachments failed to replicate when deleted and recreated
-
#753 SQLiteStorageEngine can return stale data in rare cases
-
#755 Pull replication gets stuck in Active with more completed changes than pending changes
-
#756 Pusher does not report "Forbidden" errors
-
#757 Replicator should not assume LastSequence is an integer
-
#765 Not all docs replicating with p2p .NET pull replication
-
#767 Changes feed skipping changes on rapid long poll
-
#772 ManagementException in GetWindowsName() of Platform.cs
-
#773 BrowseService’s Dispose crash fix not merged to Master?
-
#776 Replication.Stop() doesn’t release sockets
-
#779 Attachments disappearing from docs when continuous pull is enabled
-
#782 Encrypted attachments fail to push
-
#785 NullReferenceException in Replication.GetStatusFromError
-
#789 Investigate root cause of deletion not propagating to .NET client
-
#795 Set ServicePointManager.SecurityProtocol
-
#796 Headers not sent when pullReplication.Continuous = true
-
#803 NullReferenceException in WebSocketChangeTracker
-
#804 Attachment doesn’t handle non-seekable streams gracefully
-
#806 1.4 SQLite returns incorrect reason on REST API Get to purged doc
-
#807 Handle closed web sockets by reconnecting
-
#825 Pull replication doesn’t restart with web sockets
-
#826 .NET not sending all docs to a client pull replication (p2p, SSL)