Creating Indexes
Full Text Searches are supported by specially purposed indexes, which can be created either from the Couchbase Web Console, or by means of the REST API.
Indexes and Full Text Search
Every Full Text Search is performed on a user-created Full Text Index, which contains the targets on which searches are to be performed: these targets are values derived from the textual and other contents of documents within a specified bucket.
Index-creation is configurable, and can be highly selective: documents can be user-grouped into different types (for example, airline documents versus hotel documents), based on the document-IDs or the values of a designated document-field; and each document-type can be assigned its own index-mapping.
Each index-mapping in turn can be assigned its own analyzers, can be applied to a specific subset of document-fields, and can be explicitly included in or excluded from the index.
Additionally, searches can be performed across multiple buckets, by means of index aliases.
This section provides detailed explanations of how indexes can be created by means of the Couchbase Web Console. Additionally, it explains how index-creation can be achieved with the Couchbase REST API: see Index-Creation with the REST API, below.
Creating a Full Text Index
Index-creation can be performed by means of the Couchbase Web Console. The basic procedure is outlined in Searching from the UI. The current page explains the more advanced aspects of index-creation, and shows how they can be managed from the console.
Accessing and Managing Full Text Indexes
Full Text Indexes are different from the Global indexes that are accessed under the Indexes tab in the left-hand navigation panel of the Couchbase Web Console. Full Text Indexes are accessed from the Search tab: left-click on this to display the Full Text Search panel, which contains a tabular presentation of currently existing indexes, with a row for each index. (See Searching from the UI for a full illustration.) To manage an index, left-click on its row. The row expands, as follows:

Three buttons are displayed:
-
Delete causes the current index to be deleted.
-
Clone brings up the Clone Index screen, which allows the a copy of the current index to be modified as appropriate and saved under a new name.
-
Edit brings up the Edit Index screen, which allows the index to be modified. Saving modifications causes the index to be rebuilt.
Note that both the Edit Index and Clone Index screens are in most respects the same as the Add Index screen, which was itself described in Searching from the UI.
Specifying Type Identifiers
A type identifier allows the documents in a bucket to be identified by the index according to their type. When the Add Index, Edit Index, or Clone Index screen is accessed, a Type Identifier panel is displayed:
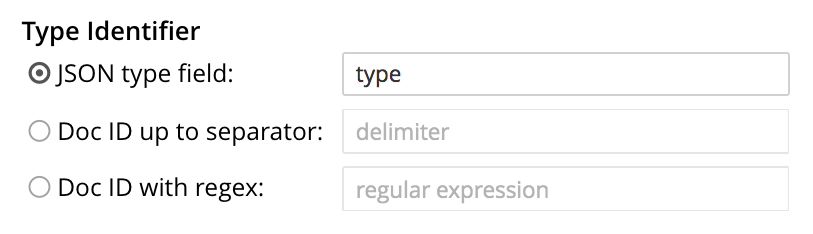
Three options are provided, each of which gives the index a particular way of determining the type of each document in the bucket:
-
JSON type field: The name of a document-field. The value specified for this field is used by the index to determine the type of the document. The default value is
type: meaning that the index searches for a field in each document whose name istype. Each document that contains a field with that name is duly included in the index, with the value of the field specifying the type of the document. Note that the value cannot be an array or JSON object. -
Doc ID up to separator: The characters in the ID of each document, up to but not including the separator. For example, if the document’s ID is
hotel_10123, the valuehotelis determined by the index to be the type of the document. The value entered into the field should be the separator-character used in the ID: for example,_, if that character is the underscore. -
Doc ID with regex: A regular expression that is applied by the index to the ID of each document. The resulting value is determined to be the type of the document. (This option may be used when the targeted document-subset contains neither a suitable JSON type field nor an ID that follows a naming convention suitable for Doc ID up to separator.) The value entered into the field should be the regular expression to be used.
Specifying Type Mappings
Whereas a type identifer tells the index how to determine the position in each document of the characters that specify the document’s type, a type mapping specifies the characters themselves.
Thus, if Doc ID up to separator is used as a type identifier, and the underscore is specified as the separator-character, a type mapping of hotel ensures that hotel_10123, rather than airline_10, is indexed.
When the Add Index, Edit Index, or Clone Index screen is accessed, the Type Mappings panel can be opened. The default setting is displayed:

Left-click on the + Add Type Mapping button. The display now appears as follows:
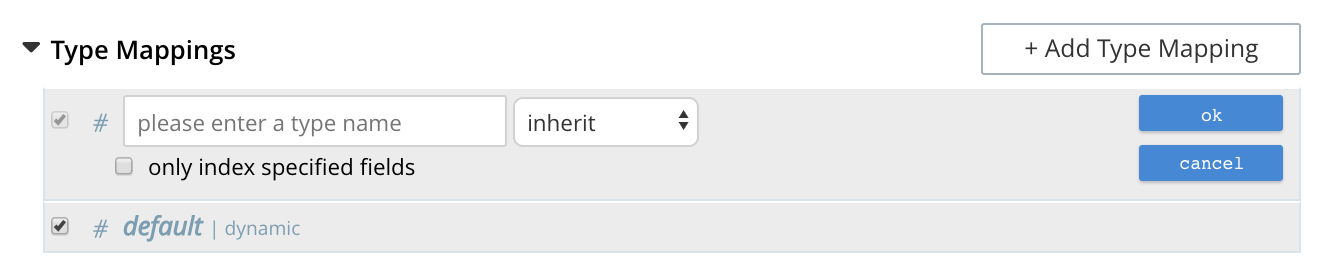
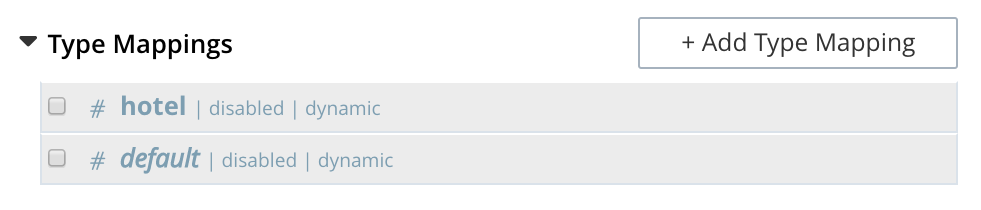
The display indicates that a single type mapping is currently defined, which is default.
This is a special type mapping created by every index automatically: it is applied to each document whose type either does not match a user-specified type mapping, or has no recognized type attribute.
Therefore, if the default mapping is left enabled, all documents are included in the index, regardless of whether the user actively specifies type mappings.
To ensure that only documents corresponding to the user’s specified type mappings are included in the index, the default type mapping must be disabled (see below for an example).
Each type mapping is listed as either dynamic, meaning that all fields are considered available for indexing; or only index specified fields, meaning that only fields specified by the user are indexed. Therefore, specifying the default index with dynamic mapping creates a large index whose response times may be relatively slow; and is, as such, an option potentially unsuitable for post-production deployments.
For information on how values are data-typed when dynamic mapping is specified, see the section below, Document Fields and Data Types.
To specify a type mapping, type an appropriate string (for example, hotel) into the interactive text field.
Note the only index specified fields checkbox: if this is checked, only user-specified fields from the document are included in the index.
(For an example, see Specifying Fields, below.)
Optionally, an analyzer can be specified for the type mapping: for all queries that do indeed support use of an analyzer, the specified analyzer will be applied, rather than the default analyzer (which is itself specified in the Advanced pane, as described below, in Specifying Advanced Settings). A list of available analyzers can be accessed and selected from, by means of the pull-down menu to the right of the interactive text-field:
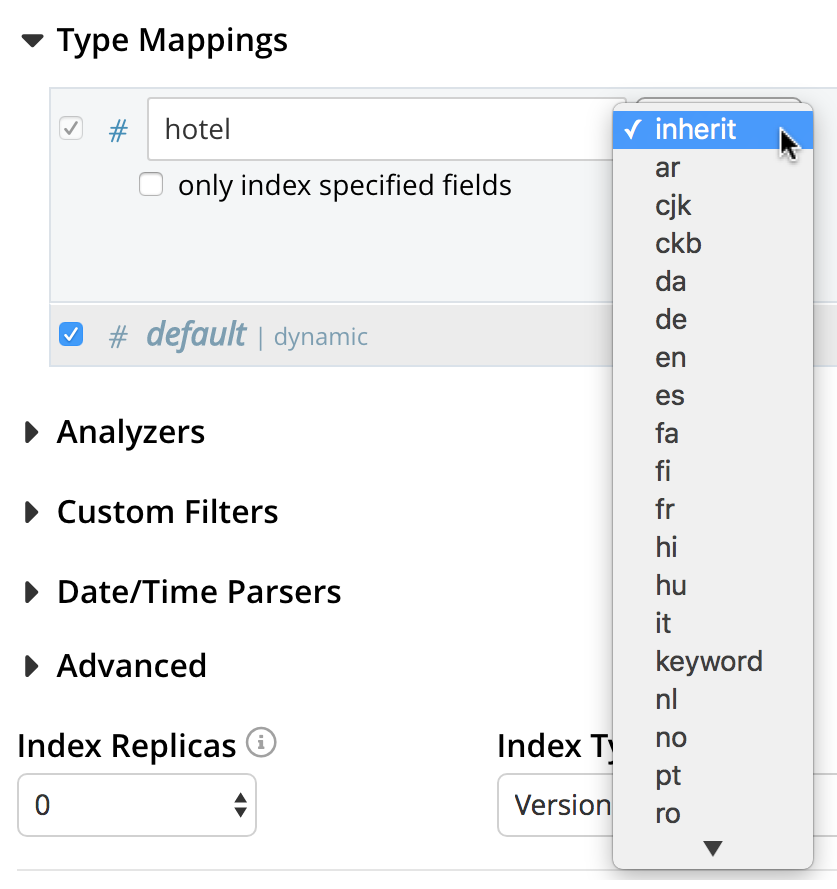
The default value, inherit, means that the type mapping inherits the default analyzer.
Note that custom analyzers can be created and stored for the index that is being defined, by means of the Analyzers panel, described below in Creating Analyzers.
On creation, all custom analyzers are available for association with a type mapping, and so appear in the pull-down menu shown above.
Additional information on analyzers can also be found on the page Understanding Analyzers.
Left-click on OK to save.
The Type Mappings panel now appears as follows:
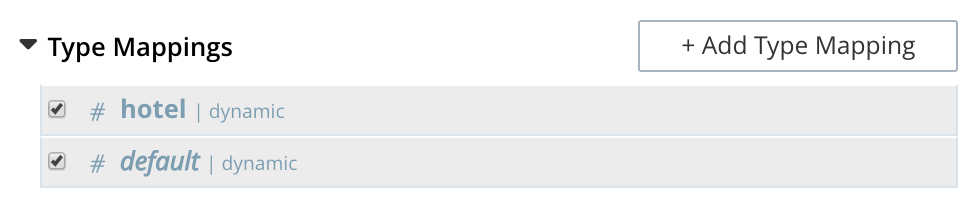
Note that the checkbox to the left of each of the two specified type mappings, hotel and default, is checked.
Because default is checked, all documents in the bucket (not merely those that correspond to the hotel type mapping) will be included in the index.
To ensure that only hotel documents are included, uncheck the checkbox for default.
The panel now appears as follows:
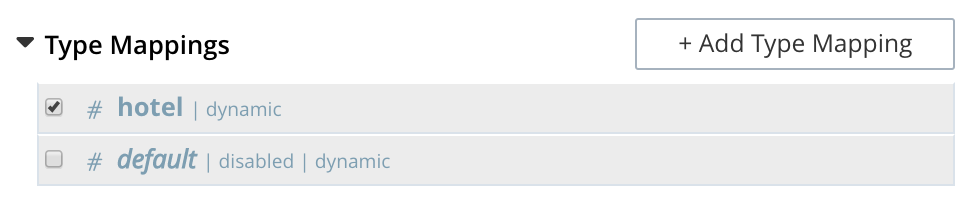
Note also that should you wish to ensure that all documents in the bucket are included in the index except those that correspond to the hotel type mapping, uncheck the checkbox for hotel:
Specifying Fields
A Full Text Index can be defined not only to include (or exclude) documents of a certain type, but also to include (or exclude) specified fields within each of the typed documents.
To specify one or more fields, hover with the mouse cursor over a row in the Type Mappings panel that contains an enabled type mapping. Buttons labeled edit and + appear:

Left-clicking on the edit button displays the following interface:
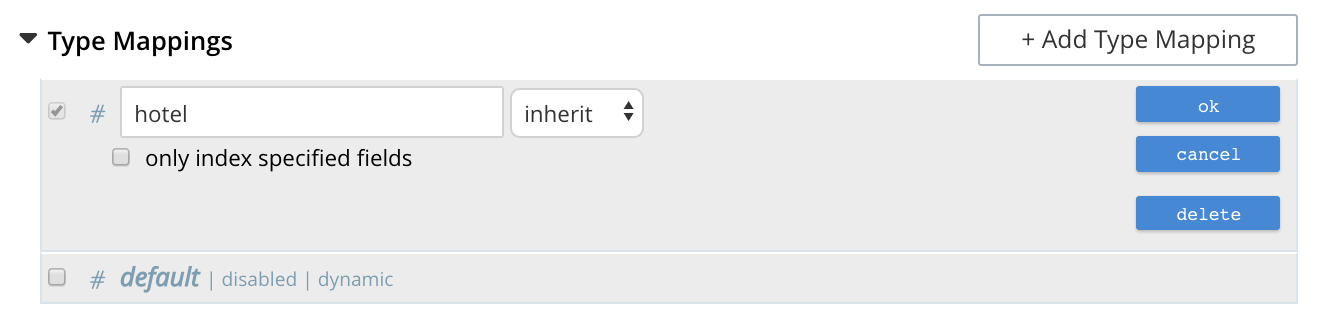
This allows the mapping to be deleted or associated with a different analyzer. If the only index specified fields checkbox is checked, only fields specified by the user are included in the index. Left-clicking on the + button displays a pop-up that features two options:

These options are described in the following sections.
Inserting a Child Field
The option insert child field allows a field to be individually included for (or excluded from) indexing, provided that it contains a single value or an array, rather than a JSON object. Selecting this option displays the following:
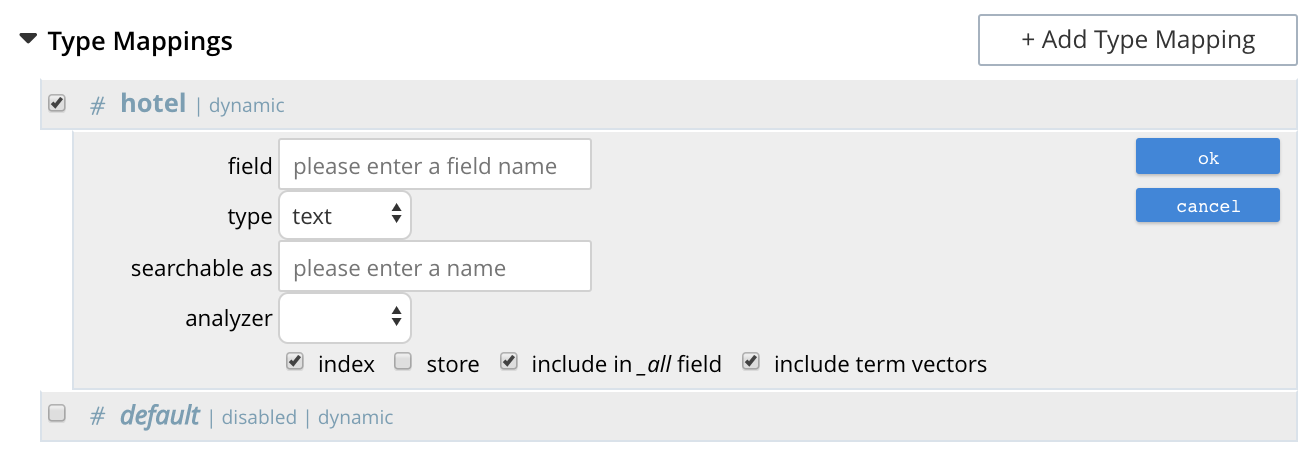
The interactive fields and checkboxes are:
-
field: The name of any field within the document that contains a single value or an array, rather than a JSON object.
-
type: The data-type of the value of the field. This can be
text,number,datetime,boolean,disabled, orgeopoint; and can be selected from the field’s pull-down menu, as follows: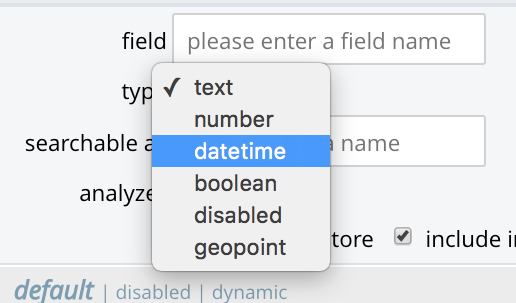
-
searchable as: Typically identical to the field (and dynamically supplied during text-input of the field-value). This can be modified, to indicate an alternative field-name, whose associated value thereby becomes included in the indexed content, rather than that associated with the field-name specified in field.
-
analyzer: An analyzer optionally to be used for the field. The list of available analyzers can be displayed by means of the field’s pull-down muenu, and so selected from.
-
index: When checked, the field is indexed; when unchecked, the field is not indexed. This may be used, therefore, to explicitly remove an already-defined field from the index.
-
store: When checked, the field-content is included in the set of values returned from a search; when unchecked, the field-content is not so included. Note that inclusion of field-content specifically permits highlighting of results, so that matched expressions can be easily seen; and generally assists in debugging procedures. However, it also results in larger indexes and longer processing-times.
-
include in all field: When checked, the field is included in the definition of _all, which is the field specified by default in the Advanced panel. When unchecked, the field is not so included. Inclusion means that when _query strings are used to specify searches, the text in the current field is searchable without the field-name requiring a prefix (thus, a search on
description:moderncan be accomplished simply by specifyingmodern). -
include term vectors: When checked, term vectors are included. When unchecked, term vectors are not included. Term vectors are the locations of terms in a particular field. Certain kinds of functionality (such as highlighting, and phrase search) require term vectors. Inclusion of term vectors results in larger indexes and correspondingly slower index build-times.
Note that when the value of the specified field is an array, the array-values are all indexed and searched individually: no special configuration is required.
The dialog, when completed, might look as follows:
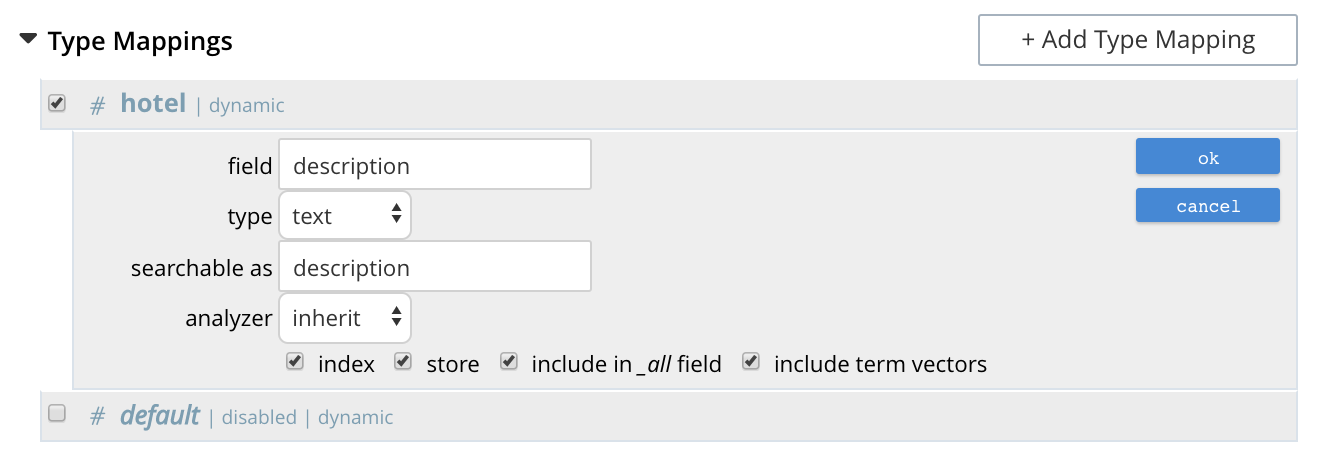
Left-click on OK. The field is saved, and its principal attributes displayed on a new row:

Note that when this row is hovered over with the mouse, an Edit button appears, whereby updates to the definition can be made.
Inserting a Child Mapping
The option insert child mapping specifies a document-field whose value is a JSON object. Selecting this option displays the following:
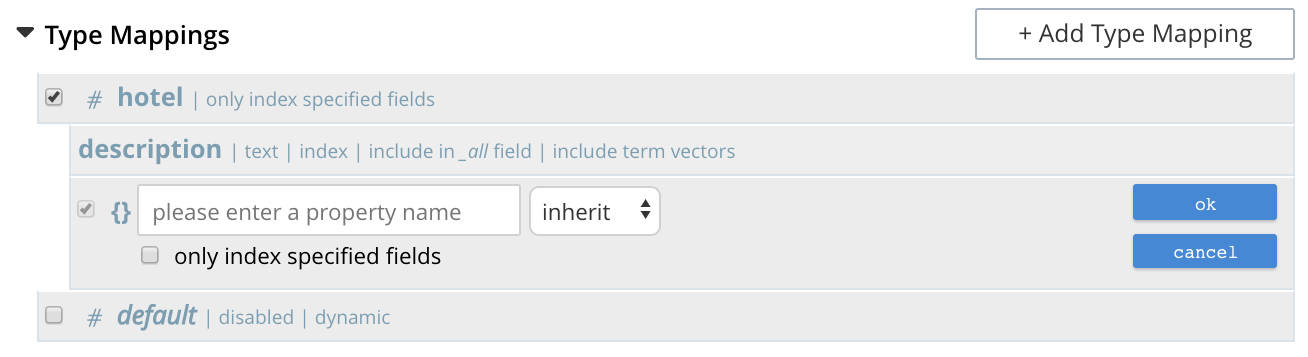
The following interactive field and checkbox are displayed:
-
{}: The name of a field whose value is a JSON object. Note that an analyzer can be specified for the field, by means of the pull-down menu.
-
only index specified fields: When checked, only fields explicitly specified are added to the index. Note that the JSON object specified as the value for {} has multiple fields of its own. Checking this box ensures that all or a subset of these can be selected for indexing.
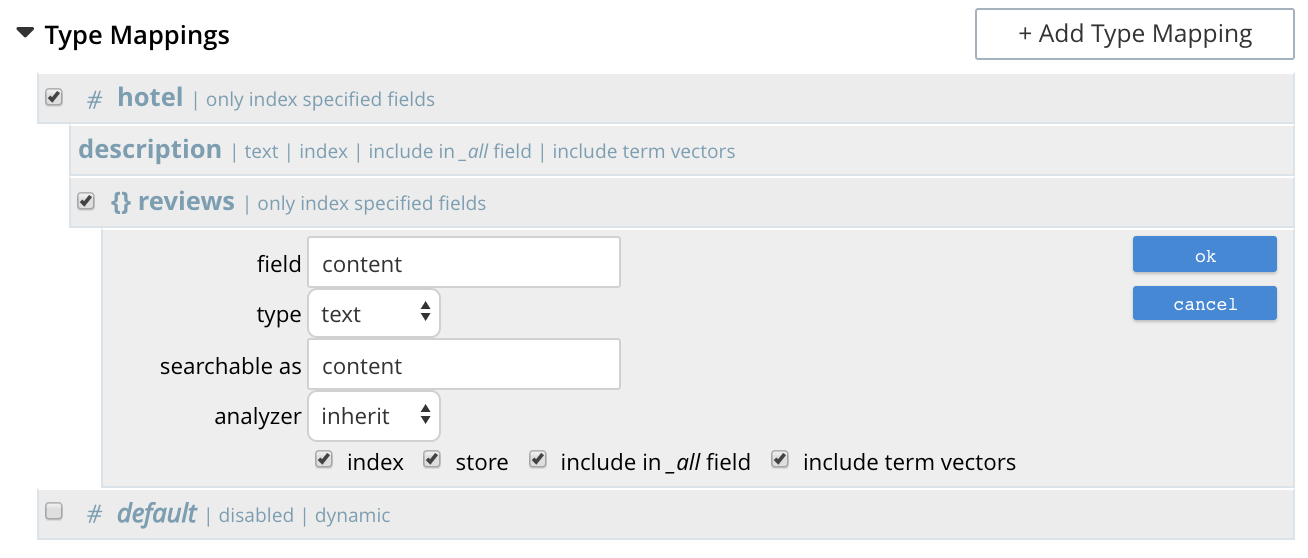
When completed, this panel might look as follows (note that reviews is a field within the hotel-type documents of the travel-sample bucket whose value is a JSON object):
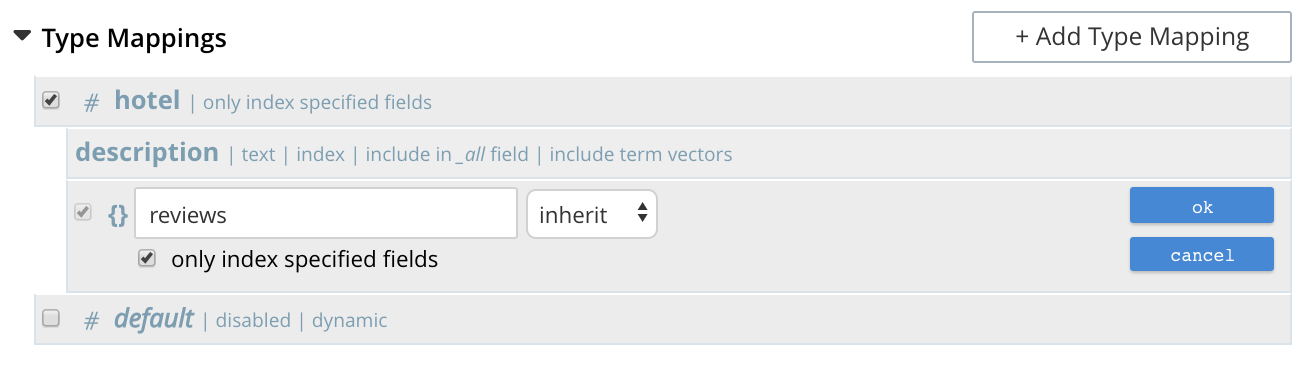
Save by left-clicking OK.
The field is now displayed as part of the hotel type mapping.
Note that by hovering over the reviews row with the mouse, the Edit and * buttons are revealed: the [.ui]* is present because reviews is an object that contains child-fields; which can now themselves be individually indexed.
Left-click on this, and a child-field, such as content, can be specified:
Creating Analyzers
Analyzers increase search-awareness by transforming input text into token-streams, which permit the management of richer and more finely controlled forms of text-matching. An analyzer consists of modules, each of which performs a particular role in the transformation (for example, removing undesirable characters; transforming standard words into stemmed or otherwise modified forms, referred to as tokens; and performing miscellaneous post-processing activities). For more information on analyzers, see Understanding Analyzers.
A default selection of analyzers is made available from the pull-down menu provided by the Type Mappings interface, discussed above. Additional analyzers can be custom-created, by means of the Analyzers panel, which appears as follows:

To create a new analyzer, left-click on the + Add Analyzer button. The Custom Analyzer dialog appears:
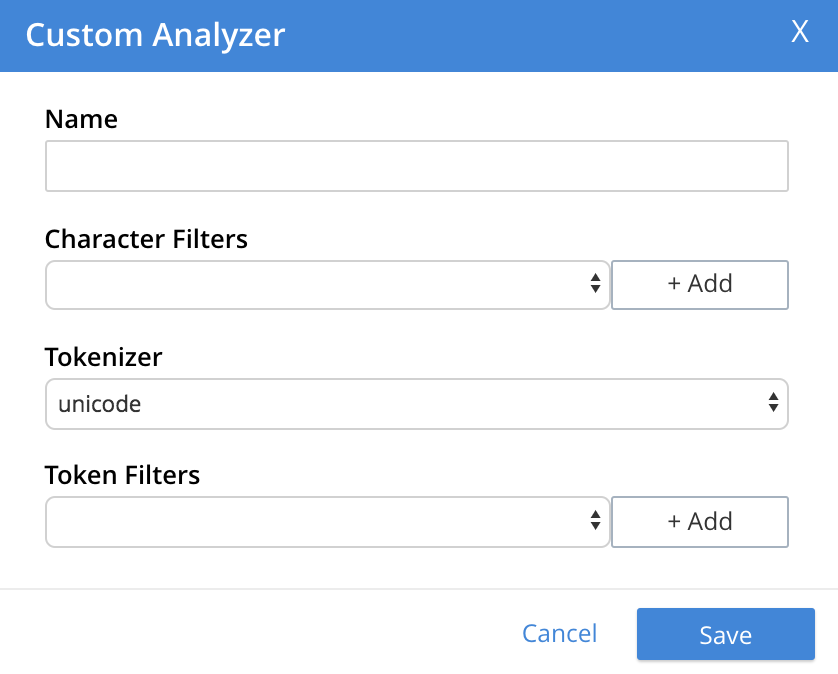
The dialog contains four interactive panels.
-
Name: A suitable, user-defined name for the analyzer.
-
Character Filters: One or more available character filters. (These strip out undesirable characters from input: for example, the
htmlcharacter filter removes HTML tags, and indexes HTML text-content alone.) To select from the list of available character filters, use the pull-down menu: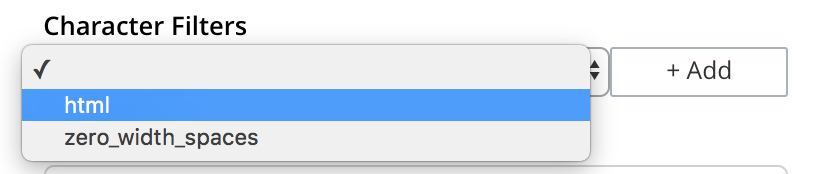
Following addition of one character filter, to add another, left-click on the + Add button, to the right of the field.
For an explanation of character filters, see the section in Understanding Analyzers.
-
Tokenizer: One of the available tokenizers. (These split input-strings into individual tokens, which together are made into a token stream. Typically, a token is established for each word.) The default value is
unicode. To select from a list of all tokenizers available, use the pull-down menu: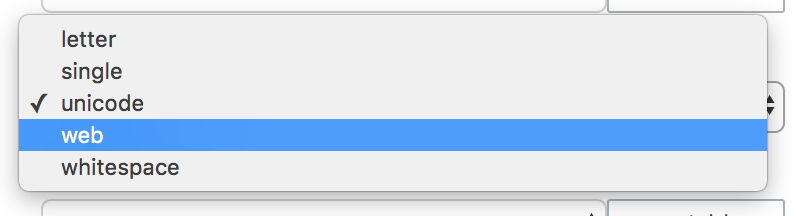
For more information on tokenizers, see the section in Understanding Analyzers.
-
Token Filter: One or more of the available token filters. (When specified, these are chained together, to perform additional post-processing on the token stream.) To select from the list of available filters, use the pull-down menu:
Following addition of one token filter, to add another, left-click on the + Add button, to the right of the field.
For more information on token filters, see the section in Understanding Analyzers.
When these fields have been appropriately completed, save; by left-clicking on the Save button. On the Edit Index screen, the newly defined analyzer now appears in the Analyzers panel, with available options displayed for further editing, and deleting. For example:

Adding Custom Filters
Custom Filters can be added, by means of the Custom Filters panel. When opened, this appears as follows:
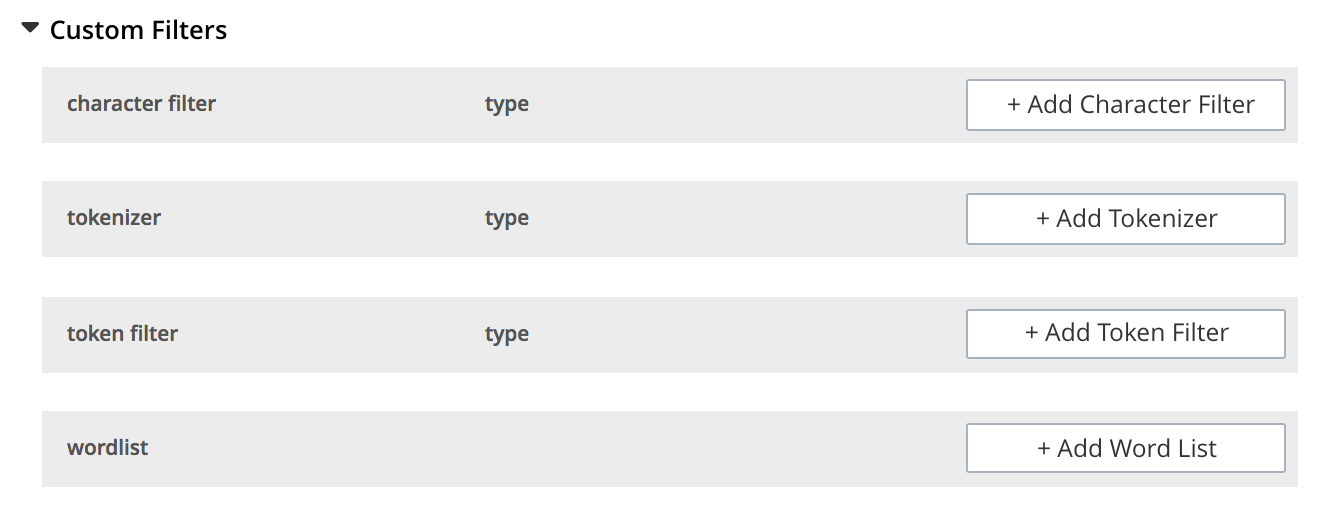
The following four options are provided:
-
character filter: Adds a new character filter to the list of those available. The new filter becomes available for inclusion in custom-created analyzers. Left-clicking on the + Add Character Filter button displays the Custom Character Filter dialog:
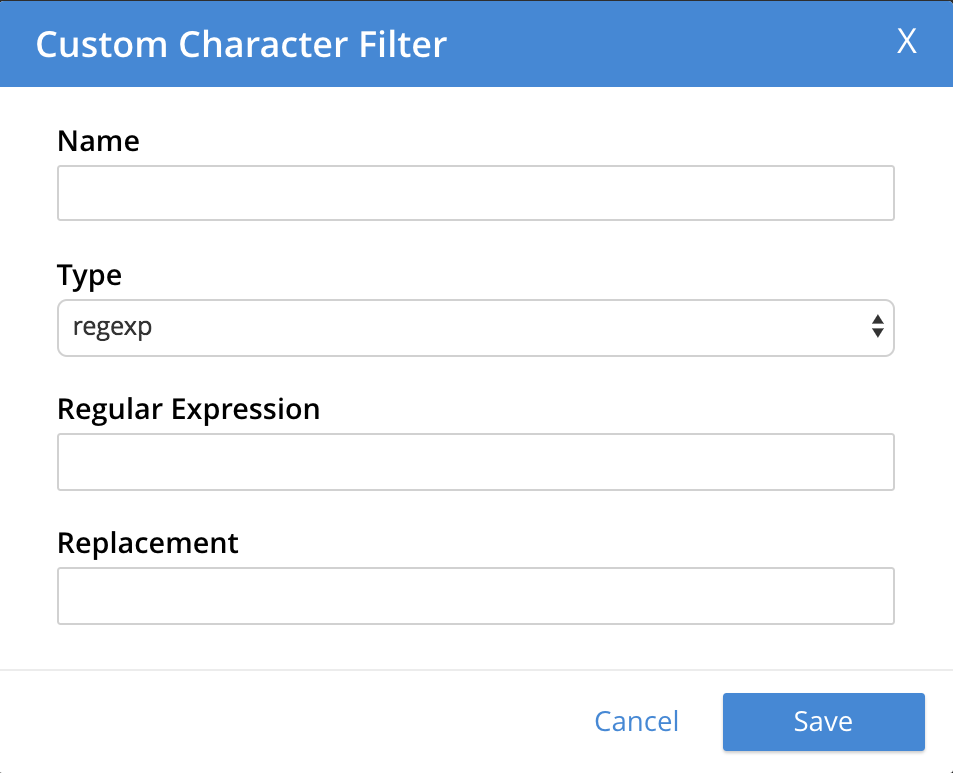
The following interactive fields are provided:
-
Name: A suitable, user-defined name for the new character filter.
-
Type: The type of filtering to be performed. Available options can be accessed from the pull-down menu, at the right of the field. (Currently, only
regexpis available.) -
Regular Expression: The specific regular expression that the new character filter is to apply. Character-strings that match the expression will be affected, others will not.
-
Replacement: The replacement text that will be substituted for each character-string match returned by the regular expression. If no replacement text is specified, the matched character-string will be omitted.
The following, completed fields define a character filter for deleting leading whitespace:
+
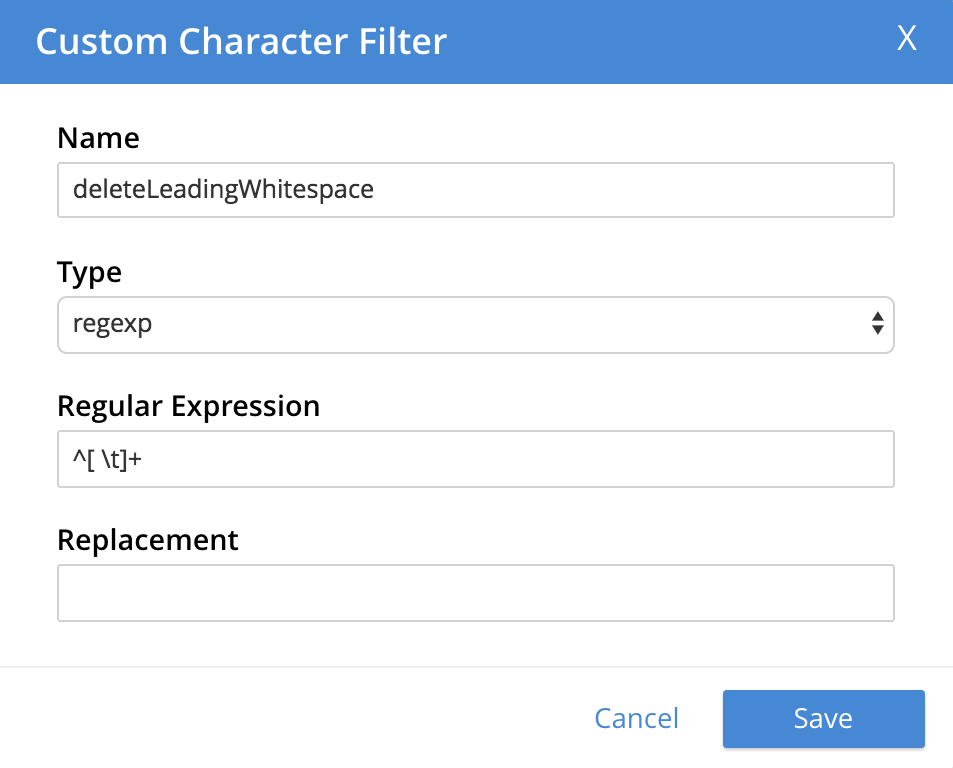
+ When saved, the new character filter is displayed on its own row, with options for further editing, and deleting:
+

-
-
tokenizer: Adds a new tokenizer to the list of those available. The new tokenizer becomes available for inclusion in custom-created analyzers. Left-clicking on the + Add Tokenizer button displays the Custom Tokenizer dialog:
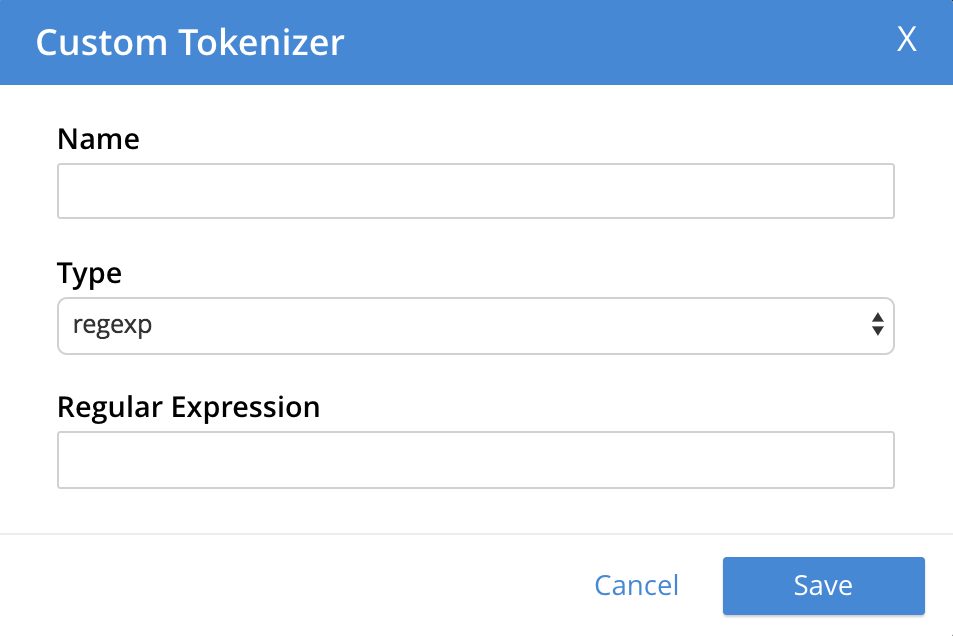
The following interactive fields are provided:
-
Name: A suitable, user-defined name for the new tokenizer.
-
Type: The process used in tokenizing. Available options can be accessed from the pull-down menu, at the right of the field. (Currently,
regexpandexceptionare available.) -
Regular Expression: The specific regular expression used by the tokenizing process.
The following, completed fields define a tokenizer that removes uppercase characters:
+
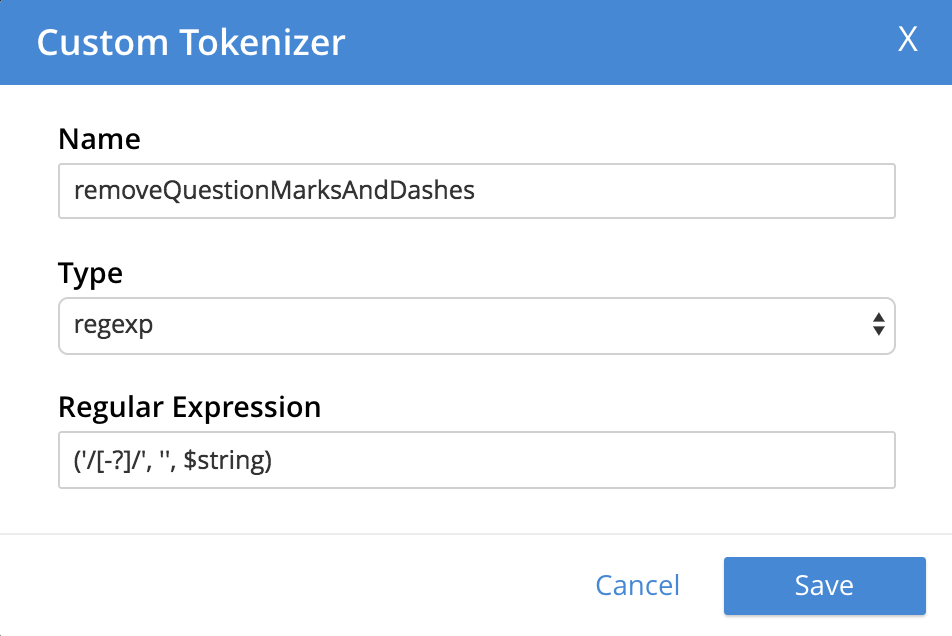
+ When saved, the new tokenizer is displayed on its own row, with options for further editing, and deleting:
+

-
-
token filter: Adds a new token filter to the list of those available. The new token filter becomes avalable for inclusion in custom-created analyzers. Left-clicking on the + Add Token Filter displays the Custom Token Filter dialog:

The following interactive fields are provided:
-
Name: A suitable, user-defined name for the new token filter.
-
Type: The type of post-processing to be provided by the new token filter. The default is
length, which creates tokens whose minimum number of characters is specified by the integer provided in the Min field, and whose maximum by the integer provided in the Max. Additional post-processing types can be selected from the pull-down menu at the right of the field: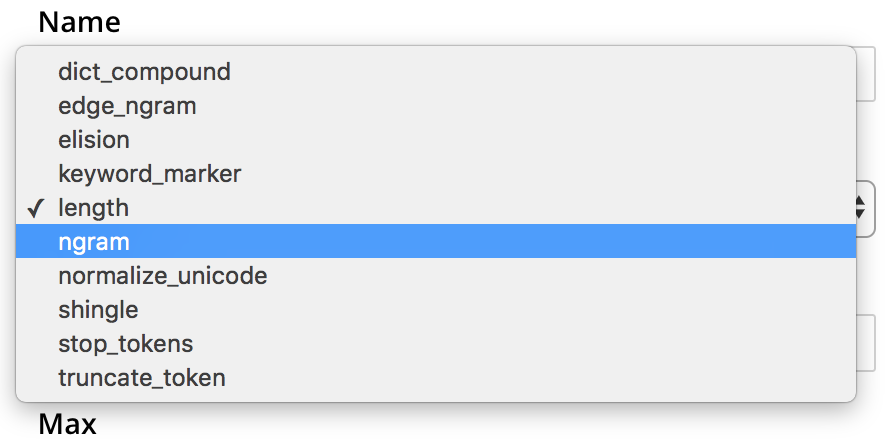
Note that type-selection determines which interactive fields appear in the Custom Token Filter dialog, following Name and Type. The pull-down menu displays a list of available types. For descriptions, see the section Token Filters, on the page Understanding Analyzers.
-
Min: The minimum length of the token, in characters. Note that this interactive field is displayed for the
lengthtype, and may not appear, or be replaced, when other types are specified. The default value is 3. -
Max: The maximum length of the token, in characters. Note that this interactive field is displayed for the
lengthtype, and may not appear, or be replaced, when other types are specified. The default value is 255.
The following, completed fields define a token filter that restricts token-length to a minimum of 3, and a maximum of 255 characters:
+

+ When saved, the new token filter is displayed on its own row, with options for further editing, and deleting:
+

-
-
wordlist: Adds a list of words to be removed from the current search. Left-clicking on the + Add Word List button displays the Custom Word List dialog:
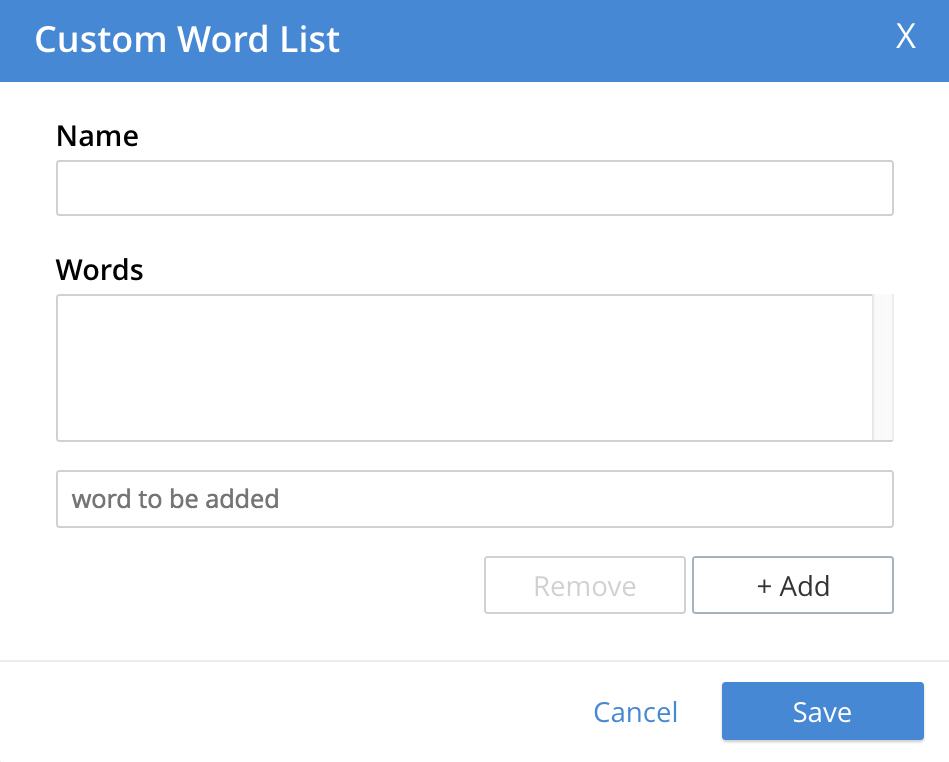
To create a custom word list, first, type a suitable name into the Name field. Then, add words by typing each individually into the field that bears the placeholder text,
word to be added. After each word has been added, left-click on the + Add button, at the lower-right. The word is added to the central Words panel. Continue adding as many words as are required. For example: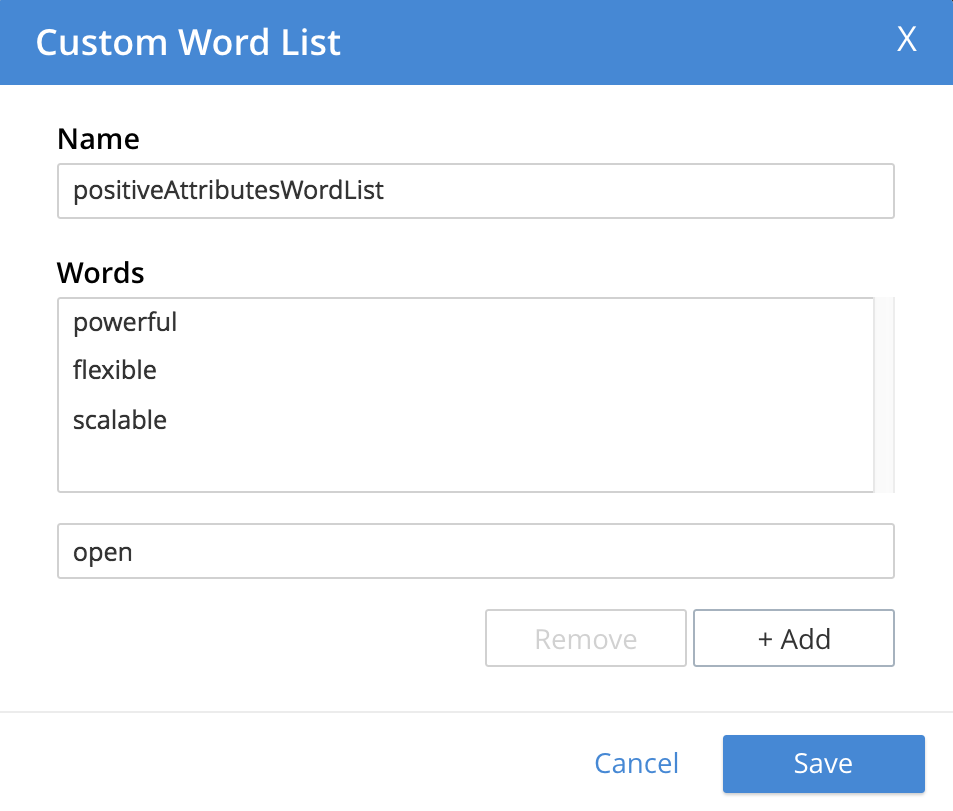
To remove a word, select the word within the Words panel, and left-click on the Remove button. To save, left-click on Save. The new word list is displayed on its own row, with options for further editing, and deleting:

Date/Time Parsers
Date/Time Parsers can be specified, to allow matches to be made across different formats:

When the + Add Date/Time Parser button is left-clicked on, the Customer Date/Time Parser dialog appears:
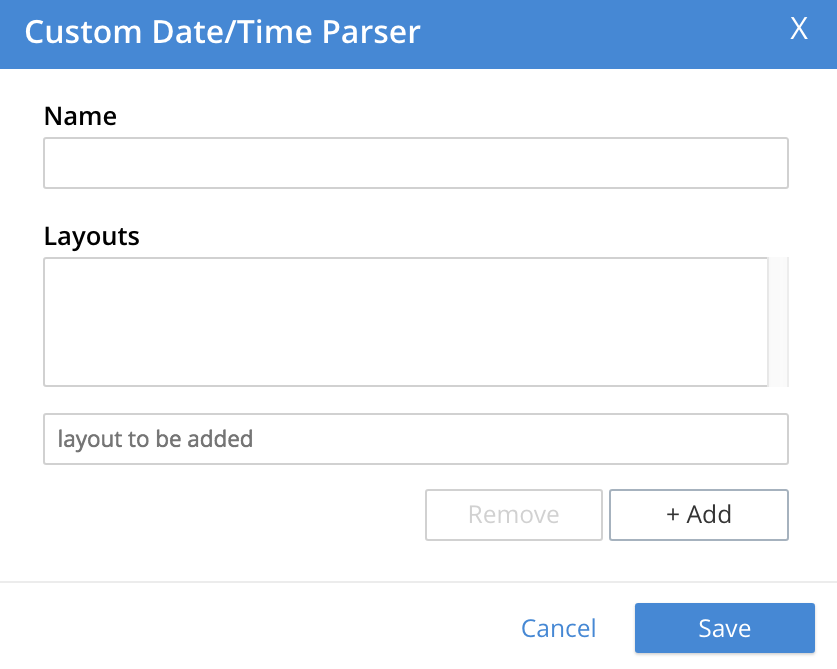
Enter a suitable name for the custom parser into the Name field. Then, successively add the layouts for the parser in the interactive field below the Layouts field, left-clicking on the + Add button after each one: this adds the layout to a list of layouts displayed in the Layouts field. To remove any of these, select its name in the Layouts field, and left-click on the Remove button. When the list is complete, left-click on the Save button, to save.
Documentation on using the Go Programming Lanaguage to specify layouts is provided on the page Package time. In particular, see the section func Parse.
Specifying Advanced Settings
Advanced settings can be specified by means of the Advanced panel. When opened, this appears as follows:
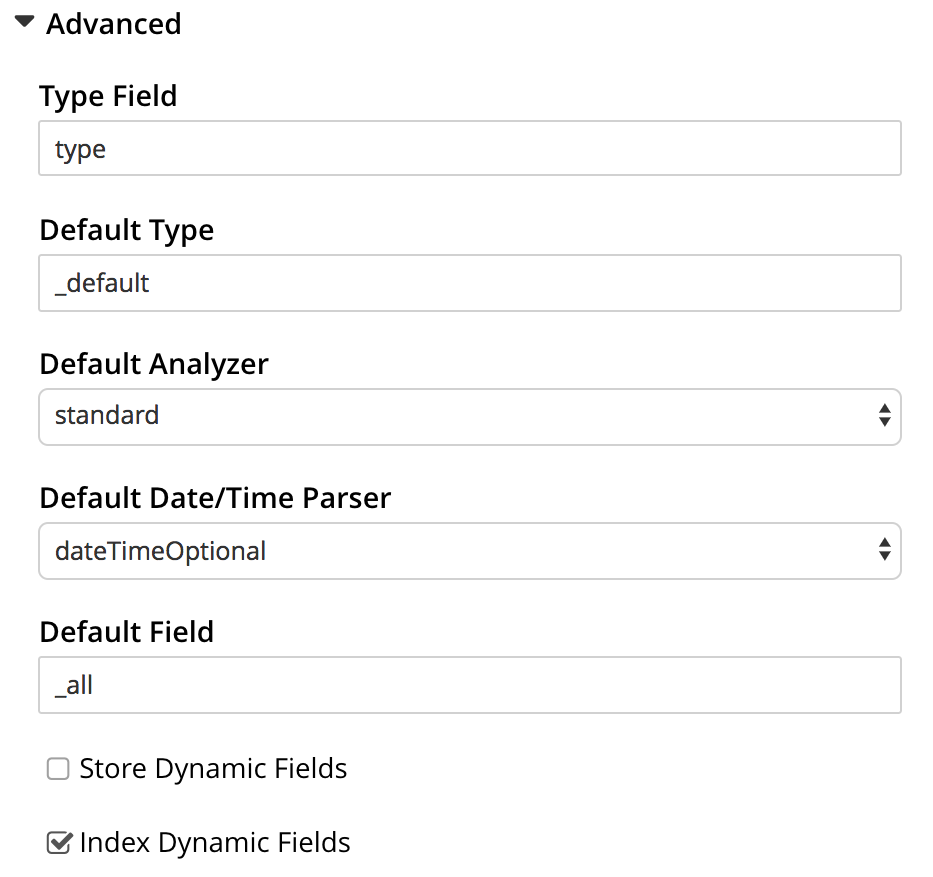
The following, interactive fields are displayed:
-
Type Field: The default type for documents in this bucket. The default value of this field is
type. -
Default Type: The default type for documents in this bucket. The default value for this field is
_default. -
Default Analyzer: The default analyzer to be used for this bucket. The default value is
standard. A list of available options can be displayed and selected from, by means of the pull-down menu at the right-hand side of the field. -
Default Date/Time Parser: The default date/time parser to be used for this bucket. The default value is
dateTimeOptional. A list of available options can be displayed and selected from, by means of the pull-down menu at the right-hand side of the field. -
Default Field: The default field for this bucket. the default value is
_all. -
Store Dynamic Fields: When checked, ensures inclusion of field-content in returned results. When unchecked, no such inclusion occurs.
-
Index Dynamic Fields: When checked, ensures dynamic fields are indexed. When unchecked, they are not indexed.
Index Replicas
The Index Replicas interface allows up to three index replicas to be selected, from a pull-down menu:
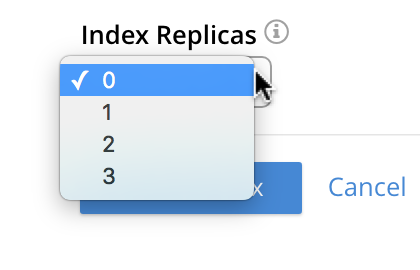
Index Replicas support availability: if an Index Service-node is lost from the cluster, its indexes may exist as replicas on another cluster-node that runs the Index Service. If an active index is lost, a replica is promoted to active status, and use of the index is uninterrupted.
Each replica must exist on a node separate from its active index, and from any other replica of that active index. Attempts to add more than the number of replicas permitted by the current cluster-configuration is not permitted, and results in an error message:
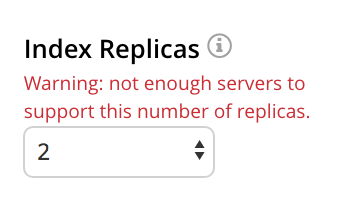
Index Type
The Index Type interface provides a pull-down menu, from which the appropriate index type can be selected:
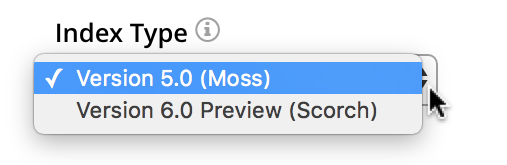
Two options are available: Version 5.0 (Moss) is the standard form of index, to be used in test, development, and production; Version 6.0 Preview (Scorch) is a preview of technology currently available for test and development only. The Version 6.0 index reduces the size of the index-footprint on disk, and provides enhanced performance for indexing and mutation-handling.
Note that the type of an index is saved in its JSON definition, which can be previewed in the Index Definition Preview panel, at the right-hand side.
Version 5.0 contains the following value for the store attribute:
"store": {
"kvStoreName": "mossStore"
},Version 6.0 contains a different value:
"store": {
"kvStoreName": "",
"indexType": "scorch"
},Using Index Aliases
An index alias points to one or more Full Text Indexes, or to additional aliases: its purpose is therefore somewhat comparable to that of a symbolic link in a filesystem. Queries on an index alias are performed on all ultimate targets, and merged results are provided.
The use of index aliases permits indirection in naming, whereby applications refer to an alias-name that never changes, leaving administrators free periodically to change the identity of the real index pointed to by the alias. This may be particularly useful when an index needs to be updated: to avoid down-time, while the current index remains in service, a clone of the current index can be created, modified, and tested. Then, when the clone is ready, the existing alias can be retargeted, so that the clone becomes the current index; and the (now) previous index can be removed.
To create an Index Alias, access the Full Text Search screen, by left-clicking on the Search tab, in the navigation bar at the left of the console. The Full Text Aliases panel is displayed in the lower section of the page:

Left-clicking on the Add Alias button displays the Add Alias screen:
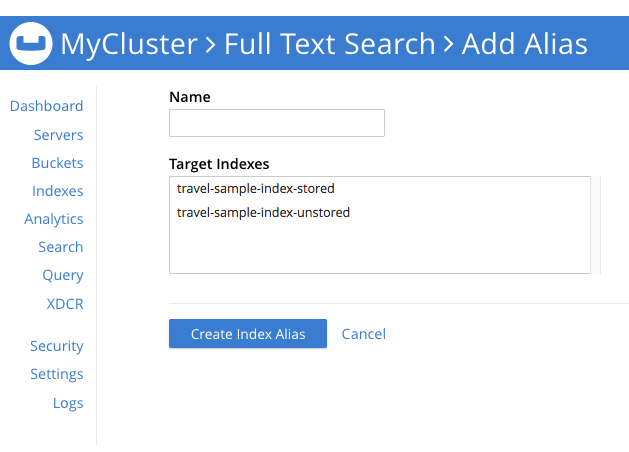
The Name field allows an appropriate name for the alias to be entered. The Target Indexes pane displays the defined indexes available to be included in the alias. To select indexes within this pane, left-click on each: when the index-name is highlighted, the index has been selected.
To create the alias, left-click on the Create Index Alias button. The saved index now appears on its own row in the Full Text Aliases area of the Full Text Search screen:
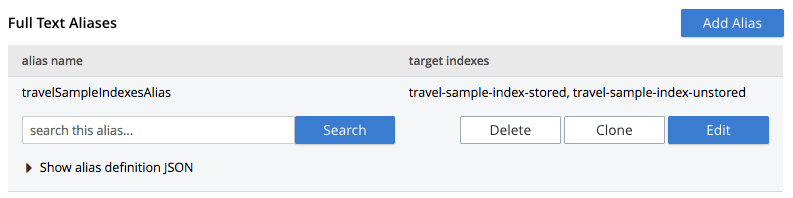
Note that when the Add Alias screen is again accessed, by left-clicking the Add Alias button, the travelSampleIndexesAlias appears in the Target Indexes panel, along with the two existing indexes.
Using the Index Definition Preview
The Index Definition Preview appears to the right-hand side of the Edit Index screen. Following index-definition, the upper portion may appear as follows:
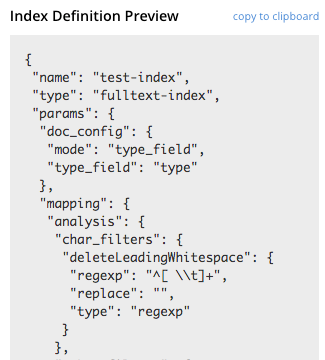
The preview consists of the JSON document that describes the current index-configuration, as created by means of the user interface. By left-clicking on the tab copy to clipboard, the definition can be saved. By means of the REST API, the saved index definition (potentially after modification) can be re-used in creation of an additional index: see the section immediately below.
Index-Creation with the REST API
The REST API can be used to create indexes. Each call requires the following:
-
An appropriate username and password.
-
Use of the verb
PUT. -
An endpoint referring to the Full Text Search service, on port
8094; and including the appropriate endpoint for index-creation as defined by the Full Text Search REST API, including the name of the new index. -
Headers to specify settings for
cache-control(no-cache) andapplication-type(application/json). -
A body containing the JSON document that defines the index to be created. This must include the name of the bucket on which the index is to be created.
The simplest way to create the appropriate JSON index-definition for the body is to create an index by means of the Couchbase Web Console, make a copy of the JSON index-definition thereby produced (by accessing the Using the Index Definition Preview, explained above), modify the index-definition as appropriate, and finally, add the index-definition to the other, preceding elements required for the call.
Note, however, that this requires modification of the uuid field; since the re-specifying of an existing field-value is interpreted as an attempted update, to an existing index.
Therefore, if the uuid field for an existing index appears in the Index Definition Preview as "uuid": "3402702ff3c862c0", it should be edited to appear "uuid": "".
A new ID will be allocated to the new index, and this ID will appear in the Index Definition Preview for the new index.
Note also that a similar condition applies to the sourceUUID field, which refers to the targeted bucket: if a new index is being created for the same bucket that was referred to in the index-object copied from the UI, the field-value can remain the same.
However, if a different bucket is now to be targeted, the field should be edited to appear "sourceUUID": ""
When specifying the endpoint for the index you are creating, make sure the path-element that concludes the endpoint is the same as that specified in the name field (which is the first field in the object).
The following curl example demonstrates the creation of an index named demoIndex, on the price field of documents of type product, within the travel-sample bucket.
It assumes that Couchbase Server is running on localhost, and that the required username and password are Administrator and password.
$ curl -u Administrator:password -XPUT \
http://localhost:8094/api/index/demoIndex \
-H 'cache-control: no-cache' \
-H 'content-type: application/json' \
-d '{
"name": "demoIndex",
"type": "fulltext-index",
"params": {
"doc_config": {
"docid_prefix_delim": "",
"docid_regexp": null,
"mode": "type_field",
"type_field": "type"
},
"mapping": {
"default_analyzer": "standard",
"default_datetime_parser": "dateTimeOptional",
"default_field": "_all",
"default_mapping": {
"dynamic": true,
"enabled": false
},
"default_type": "_default",
"index_dynamic": true,
"store_dynamic": false,
"types": {
"product": {
"dynamic": true,
"enabled": true,
"properties": {
"price": {
"enabled": true,
"dynamic": false,
"fields": [
{
"analyzer": "",
"include_in_all": true,
"include_term_vectors": true,
"index": true,
"name": "price",
"store": false,
"type": "number"
}
]
}
}
}
}
},
"store": {
"kvStoreName": "mossStore"
}
},
"sourceType": "couchbase",
"sourceName": "travel-sample",
"sourceUUID": "99e9829898a45ba35f1c9c85dfcdb42b",
"sourceParams": {},
"planParams": {
"maxPartitionsPerPIndex": 171,
"numReplicas": 0
},
"uuid": ""
}'If the call is successful, the following object is returned:
{"status":"ok"}The newly created index can then be inspected in the Couchbase Web Console.
Document-Fields and Data-Types
During index-creation, for each document-field for which the data-type has not been explicitly specified (which is to say, text, number, datetime, boolean, disabled, or geopoint), the field-value is examined, and the best-possible determination made, as follows:
| Type of JSON value | Indexed as... |
|---|---|
Boolean |
Boolean |
Number |
Number |
String containing a date |
Date |
String (not containing a date) |
String |
Note that the indexer attempts to parse String date-values as dates, and indexes them as such if the operation succeeds. Note, however, that on query-execution, Full Text Search expects dates to be in the format specified by RFC-3339, which is a specific profile of ISO-8601.
Note also that String values such as 7 or true are not respectively indexed as numbers or Booleans: they remain as Strings.
The number-type is modeled as a 64-bit floating-point value internally.