Pushdowns
N1QL Query Engine implements many query processing optimizations to achieve the best possible performance for N1QL queries. The GSI Indexes are a vital part of query performance and are tightly coupled with the N1QL engine.
Index Pushdowns are performance optimizations where the N1QL engine pushes more of the work down to the Indexer. Query Indexer not only indexes data, it also supports various operations such as point scans, range scans, array indexing, sort order, and pagination. N1QL tries to leverage the indexer functionality as much as possible by pushing down the operations to indexer as part of the index scan. This helps performance, predominantly, in two ways:
-
Minimize the amount of data transferred from Indexer nodes to Query nodes.
-
Minimize the amount of processing done at Query nodes.
Index Projection
(Introduced in Couchbase Server 5.0)
When processing a SELECT or DML with a where clause, the N1QL engine picks one or more qualified indexes to be used for the query.
Note that each index will have document field names explicitly specified as index-keys, and some metadata fields, such as meta().id, implicitly stored in the index.
In earlier releases, the Indexer used to return all index-keys available in the index for the matching documents.
From Couchbase Server 5.0, N1QL requests the exact list of fields needed for the query.
For a covered query, it is the fields referred in projection, predicate, GROUP BY clauses, ORDER BY clauses, HAVING clauses, ON key, and subqueries of the query.
For non-covered queries, it is just META().id.
For example, consider the following index and query:
C1: CREATE INDEX `def_route_src_dst_day`
ON `travel-sample`(`sourceairport`,`destinationairport`,
(distinct (array (`v`.`day`) for `v` in `schedule` end)))
WHERE (`type` = "route") ;
Q1: EXPLAIN SELECT sourceairport FROM `travel-sample`
USE INDEX (def_route_src_dst_day)
WHERE sourceairport = "SFO"
AND type = "route"
LIMIT 1;
Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "DistinctScan",
"limit": "1",
"scan": {
"#operator": "IndexScan2",
"covers": [
"cover ((`travel-sample`.`sourceairport`))",
"cover ((`travel-sample`.`destinationairport`))",
"cover ((distinct (array (`v`.`day`) for `v` in (`travel-sample`.`schedule`) end)))",
"cover ((meta(`travel-sample`).`id`))"
],
"filter_covers": {
"cover ((`travel-sample`.`type`))": "route"
},
"index": "def_route_src_dst_day",
"index_id": "4e6f8ae011d8efc8",
"index_projection": {
"entry_keys": [
0
],
"primary_key": true
},
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"SFO\"",
"inclusion": 3,
"low": "\"SFO\""
}
]
}
],
"using": "gsi"
}
},
...The query refers to fields sourceairport and type.
The index is wider in scope, that is, it has sourceairport, destinationairport, schedule.day, and type fields.
So, for each matching document, the query requires only a subset of the data stored in the index. With index-projection support, N1QL indicates the exact data requested as part of the index-scan. In this example,
-
entry_keysin the EXPLAIN output indicates the exact index-key fields that should be returned in the index-scan result. This has only one entry0indicating the first index-keysourceairport. -
Also, the
primary_keyindicates whether the index should return the primary keymeta().idof the matching document. Note that in some cases (such as whendistinctScanorintersectScanare used, as in the above example), themeta().idmay be retrieved even though the query doesn’t explicitly specify it in the query:"index_projection": { "entry_keys": [ 0 ], "primary_key": true }
Without this optimization, index-scan would return all the index-keys defined in the index.
If the index_projection field is missing in the EXPLAIN output, then Indexer would return all index-keys.
Predicate Pushdown
N1QL query engine and GSI indexes support many optimizations for efficiently processing predicate push-downs. In general, this performance optimization is leveraged when N1QL decides to use an Index-scan for processing a query, and whole or partial predicate can be pushed to the indexer to filter documents of interest to the query.
For example, in the above query Q1 with a simple WHERE clause, the predicate (sourceairport = "SFO") is pushed to the index C1 with the following single span and range.
These attributes exactly define different characteristics of the index scan:
-
Excerpt from the EXPLAIN output with
spanandrange:"spans": [ { "exact": true, "range": [ { "high": "\"SFO\"", "inclusion": 3, "low": "\"SFO\"" } ] } ] -
Each Span defines details about one index-key summarizing corresponding predicate conditions into a range-scan lookup for the index. In this example, the predicate condition (
sourceairport = "SFO") translates to one span with one range that specifies bothlowandhighvalues of "SFO" (to imply equals condition). -
Refer to section Scans for more information.
Composite Predicate Pushdown
Compound or composite predicates are those with multiple conditions on different fields of the document.
When the predicate is conjunctive with multiple AND conditions, then a single span with multiple ranges are specified in the index-scan request.
When the predicate is disjunctive, then multiple spans are specified.
See Scans
for more details and examples on how predicate pushdown works for various types of index-scans as well as the conjunctive predicate AND and the disjunctive predicate OR.
Index key order and structure
Composite indexes have more than one index key, and the order of the index keys is important for any lookup or scan of the index, because the indexes structure all the indexed entries in linearized default collation sorted order of all the index-keys. For example, consider the following index:
CREATE INDEX `idx_age_name` ON users(age, name);
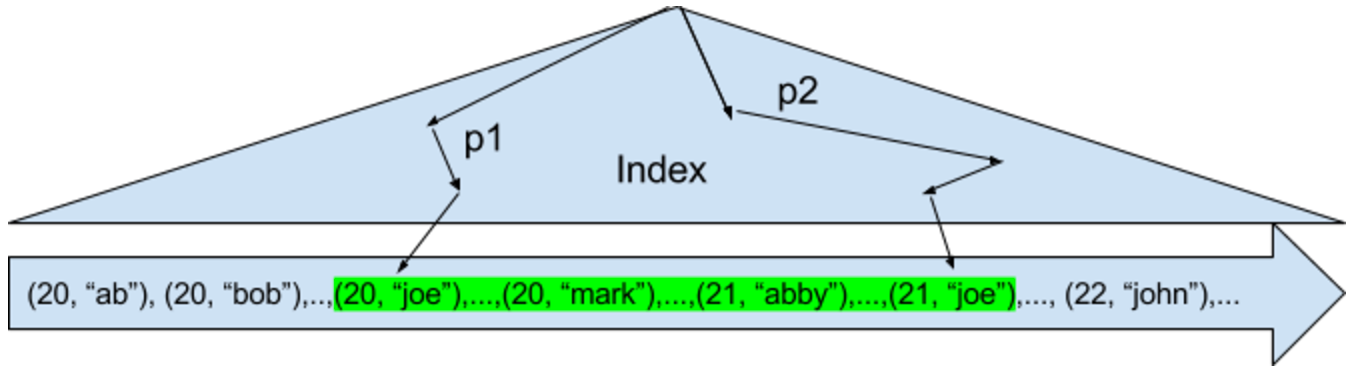
Various age and name values are stored in the index in a tree like structure (represented by the triangle in the above picture) with all the index key values linearly sorted as ordered pairs. For instance,
-
The above picture shows index-entries with all names in sorted order with an age of 20 followed by the entries for age 21 and related names.
-
The arrowed paths logically depicts how an index lookup or scan would find entries in the index.
-
A point lookup query for
age=20 AND name="joe"may follow arrows labelled p1. -
Similarly, a range scan for
(age BETWEEN 20 and 21) AND (name="joe")may find entries of interest between the paths labelled p1 and p2 (highlighted in green).This range may include some unwanted entries (such as "mark", "abby", "anne") which will be filtered subsequently. Queries with predicates such as (age = 20) AND (name BETWEEN "joe" and "mark")will need all the entries found using range scans.
In general, when the predicate has a range condition on prefixing index-keys (such as age) may produce unwanted results from the range-scan index-lookups.
In couchbase Server 5.0, the N1QL and Indexer are enhanced with complete and accurate predicate pushdown to filter such unnecessary results in Indexer itself.
This improves query performance as it saves the additional overhead in transferring the unwanted data/results to query nodes and subsequently filtering the results in N1QL.
This is explained with an example in the following document
Composite predicate with range-scan on prefix index-keys.
| In couchbase server 4.x, indexer would return such extraneous unwanted results and N1QL would filter them, thus guaranteeing accurate final query results. |
Composite predicate with range-scan on prefix index-keys
N1QL supports efficient predicate pushdown to indexes in the cases when the WHERE clause has a range predicate on any of the prefixing index-keys.
Consider the following query which finds all destination airports within 2000 miles of LAX.
CREATE INDEX `def_route_src_dst_dist`
ON `travel-sample`(`distance`,`sourceairport`,`destinationairport`)
WHERE (`type` = "route");
EXPLAIN SELECT destinationairport
FROM `travel-sample`
USE INDEX (def_route_src_dst_dist)
WHERE type = "route"
AND distance < 2000 AND sourceairport = "LAX";
Results:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"covers": [
"cover ((`travel-sample`.`distance`))",
"cover ((`travel-sample`.`sourceairport`))",
"cover ((`travel-sample`.`destinationairport`))",
"cover ((meta(`travel-sample`).`id`))"
],
"filter_covers": {
"cover ((`travel-sample`.`type`))": "route"
},
"index": "def_route_src_dst_dist",
"index_id": "d0f5a70e29f09ca1",
"index_projection": {
"entry_keys": [
0,
1,
2
]
},
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "2000",
"inclusion": 0,
"low": "null"
},
{
"high": "\"LAX\"",
"inclusion": 3,
"low": "\"LAX\""
}
]
}
],
"using": "gsi"
},
...
}In this query:
-
The predicate has the range condition on the first index-key
distanceand an equality predicate on the 2nd index-keysourceairport. -
The predicate is accurately represented and pushed-down to indexer, as shown in the
spansattribute of the EXPLAIN query plan output. Therange[]attribute is an array of the predicate bounds for individual index-keys involved in the compound predicate.-
The first element of
range[]corresponds to the index-keydistancewith (low,high) values (null,2000) respectively. -
The second element of
range[]corresponds to the index-keysourceairportwith (low,high) values ("LAX","LAX") representing equals condition.
-
-
Indexer processes the lookup request and exactly returns only the documents matching the predicate conditions. For example, when you enable monitoring with the N1QL configuration parameter
profile = "timings"for this query, you can see that indexer returns 165 documents which is same as the final result set of the query."~children": [ { "#operator": "IndexScan2", "#stats": { "#itemsOut": 165, "#phaseSwitches": 663, "execTime": "174.449µs", "kernTime": "22.49046ms" }, "index": "def_route_src_dst_dist", "index_id": "d0f5a70e29f09ca1", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "2000", "inclusion": 0, "low": "null" }, { "high": "\"LAX\"", "inclusion": 3, "low": "\"LAX\"" } ] } ], "using": "gsi", ... { "#operator": "FinalProject", "#stats": { "#itemsIn": 165, "#itemsOut": 165, "#phaseSwitches": 667, "execTime": "60.055µs", "kernTime": "31.413071ms" }, ...
Pagination Pushdown
Pagination in N1QL queries is achieved by using the LIMIT and OFFSET clauses, and both of the operators can be pushed to indexer whenever possible. These operators may not always be pushed to Indexer, depending on the following factors:
-
Whether or not the whole predicate in the WHERE clause can be completely and accurately pushed to a single index.
-
When using IntersectScan, N1QL uses multiple indexes to process the query. As such, LIMIT/OFFSET will need to be processed in N1QL at a later stage of query processing, and hence cannot be pushed to the Indexer.
-
Whether or not the SELECT query has other clauses that may impact pagination, such as ORDER BY or JOIN. For example,
-
When ORDER BY key in the query is different from that of the index order, then the query layer will need to process the sort; and hence, in those cases, the pagination cannot be pushed to the indexer as shown in Example 3 below.
-
For JOIN queries, index scans can be used only for the left side keyspace. Subsequent JOIN phrases may filter some documents, after which only LIMIT/OFFSET can be applied. Hence, the pagination operators cannot be pushed when a query has JOIN clauses.
-
LIMIT pushdown is supported in Couchbase Server 4.5.0 versions.
OFFSET pushdown is introduced in Couchbase Server 5.0.
Both LIMIT and OFFSET may not be pushed to index in all cases. For example, when pushing to the primary index, only LIMIT is pushed (see Example 2 below). Observe that, in that case, LIMIT is pushed with the value of the sum of the limit and offset specified in the query. This may not be as efficient because N1QL will need to drop the first offset number of documents.
Example 1: When using secondary index, both LIMIT and OFFSET operators are pushed to index.
EXPLAIN SELECT * FROM `travel-sample`
WHERE city = "San Francisco"
OFFSET 4000 LIMIT 10000;
Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"index": "def_city",
"index_id": "fd399cb179e9ab0a",
"index_projection": {
"primary_key": true
},
"keyspace": "travel-sample",
"limit": "10000",
"namespace": "default",
"offset": "4000",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"San Francisco\"",
"inclusion": 3,
"low": "\"San Francisco\""
}
]
}
],
"using": "gsi"
}Example 2: When using a primary index, only LIMIT is pushed.
EXPLAIN SELECT * FROM `travel-sample`
OFFSET 4000 LIMIT 10000;
Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "PrimaryScan",
"index": "def_primary",
"keyspace": "travel-sample",
"limit": "(10000 + 4000)",
"namespace": "default",
"using": "gsi"
}Example 3: LIMIT and OFFSET operators are not pushed to index when index order is different from that specified in the ORDER BY.
EXPLAIN SELECT * FROM `travel-sample`
USE INDEX(def_city)
WHERE city = "San Francisco"
ORDER BY name
OFFSET 4000 LIMIT 10000;
Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"index": "def_city",
"index_id": "931a0fae2fe4ef8",
"index_projection": {
"primary_key": true
},
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"San Francisco\"",
"inclusion": 3,
"low": "\"San Francisco\""
}
]
}
],
"using": "gsi"
},
{
"#operator": "Fetch",
"keyspace": "travel-sample",
"namespace": "default"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Filter",
"condition": "((`travel-sample`.`city`) = \"San Francisco\")"
},
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "self",
"star": true
}
]
}
]
}
}
]
},
{
"#operator": "Order",
"limit": "10000",
"offset": "4000",
"sort_terms": [
{
"expr": "(`travel-sample`.`name`)"
}
]
},
{
"#operator": "Offset",
"expr": "4000"
},
{
"#operator": "Limit",
"expr": "10000"
},
{
"#operator": "FinalProject"
}
]
},
"text": "SELECT * FROM `travel-sample` \nUSE INDEX(def_city)\nWHERE city =
\"San Francisco\"\nORDER BY name\nOFFSET 4000 LIMIT 10000;"
}Using Index Order
N1QL may avoid ORDER BY processing in cases where the ordering of entries in the index can be leveraged for the query. N1QL carefully evaluates each query to decide whether ORDER BY keys are aligned with the index key order. For example, ORDER BY may not be pushed down when the ORDER BY fields are not aligned with the index-key order defining the index.
In the following example, you can see that the query Q1 plan does not have an ORDER operator before the final projection.
That means, order pushdown is being leveraged, and the query is relying on the index order.
However, for Q2, you can see an additional ORDER operator before the final projection, because the ORDER BY field meta().id is different from the index order key city.
Q1: Find all cities that start with "San", and sort the results by the city name in ascending order.
EXPLAIN SELECT city FROM `travel-sample`
WHERE city LIKE "San%"
ORDER BY city;
Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"covers": [
"cover ((`travel-sample`.`city`))",
"cover ((meta(`travel-sample`).`id`))"
],
"index": "def_city",
"index_id": "fd399cb179e9ab0a",
"index_projection": {
"entry_keys": [
0
]
},
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"Sao\"",
"inclusion": 1,
"low": "\"San\""
}
]
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"maxParallelism": 1,
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Filter",
"condition": "(cover ((`travel-sample`.`city`)) like \"San%\")"
},
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "cover ((`travel-sample`.`city`))"
}
]
},
{
"#operator": "FinalProject"
}
]
}
}
]
}
]
},
"text": "SELECT city FROM `travel-sample` \nWHERE city LIKE \"San%\"\nORDER BY city;"
}Q2: Find all cities that start with "San", and sort the results by the document primary key in ascending order.
EXPLAIN SELECT city FROM `travel-sample`
WHERE city LIKE "San%"
ORDER BY meta().id;
Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"covers": [
"cover ((`travel-sample`.`city`))",
"cover ((meta(`travel-sample`).`id`))"
],
"index": "def_city",
"index_id": "fd399cb179e9ab0a",
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"Sao\"",
"inclusion": 1,
"low": "\"San\""
}
]
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Filter",
"condition": "(cover ((`travel-sample`.`city`)) like \"San%\")"
},
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "cover ((`travel-sample`.`city`))"
}
]
}
]
}
}
]
},
{
"#operator": "Order",
"sort_terms": [
{
"expr": "cover ((meta(`travel-sample`).`id`))"
}
]
},
{
"#operator": "FinalProject"
}
]
},
"text": "SELECT city FROM `travel-sample` \nWHERE city LIKE \"San%\"\nORDER BY meta().id;"
}Limitation: Currently N1QL supports order pushdown only when the ORDER BY keys are aligned with the Index order.
But reverse-scan of the index is not supported.
For example, as shown in the EXPLAIN output of Q1 above, an additional "order" operator is not required, because the index order is the same as the ascending order specified in Q1.
Similarly, in the following query Q3, the ORDER BY clause has DESC, and that matches with the index order defined by the index C3.
However, the ASC order in Q1 will not be able to leverage the index order in the index def_city_desc, nor the DESC order in Q3 will be able to leverage the index order in the index def_city
C3: CREATE INDEX def_city ON `travel-sample`(`city` DESC);
Q3: Descending variation of Q1.
EXPLAIN SELECT city FROM `travel-sample`
WHERE city LIKE "San%"
ORDER BY meta().id;
Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"covers": [
"cover ((`travel-sample`.`city`))",
"cover ((meta(`travel-sample`).`id`))"
],
"index": "def_city",
"index_id": "fd399cb179e9ab0a",
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"Sao\"",
"inclusion": 1,
"low": "\"San\""
}
]
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Filter",
"condition": "(cover ((`travel-sample`.`city`)) like \"San%\")"
},
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "cover ((`travel-sample`.`city`))"
}
]
}
]
}
}
]
},
{
"#operator": "Order",
"sort_terms": [
{
"expr": "cover ((meta(`travel-sample`).`id`))"
}
]
},
{
"#operator": "FinalProject"
}
]
},
"text": "SELECT city FROM `travel-sample` \nWHERE city LIKE \"San%\"\nORDER BY meta().id;"
}Operator Pushdowns
The N1QL query engine tries to avoid unnecessary processing operators such as MIN(), MAX(), and COUNT(), which can be processed by Indexer much more efficiently. In such cases, N1QL pushes down necessary hints or options to the Indexer to process the following operators.
MAX() Pushdown
(Introduced in Couchbase Server 5.0)
This function returns the highest value of the input field based on the default collation rules (for details, see Data types and Comparison Operators)
MAX() can be pushed to the Indexer only when the index is created with matching index keys in descending order.
In such cases, the maximum value will be the first entry in the Index when keys are in descending order, so the N1QL engine will automatically add the hint Limit: 1 to the index scan.
In the EXPLAIN output of the query, you can see the limit hint.
Example 1: Uses the def_city index that comes pre-installed and can be made by the statement:
USE INDEX def_city ON `travel-sample`(city DESC);Example 1a: MAX of a string field – Finding the alphabetically highest city name in travel-sample.
CREATE INDEX idx_city_desc ON `travel-sample`(city DESC);
EXPLAIN SELECT MAX(city)
FROM `travel-sample`
USE INDEX (def_city)
WHERE city is not null;Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"covers": [
"cover ((`travel-sample`.`city`))",
"cover ((meta(`travel-sample`).`id`))"
],
"index": "def_city",
"index_id": "e0a377e15a408175",
"index_projection": {
"entry_keys": [
0
]
},
"keyspace": "travel-sample",
"limit": "1", / this line is an added hint
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"inclusion": 0,
"low": "null"
}
]
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Filter",
"condition": "(cover ((`travel-sample`.`city`)) is not null)"
},
{
"#operator": "InitialGroup",
"aggregates": [
"max(cover ((`travel-sample`.`city`)))"
],
"group_keys": []
}
]
}
},
{
"#operator": "IntermediateGroup",
"aggregates": [
"max(cover ((`travel-sample`.`city`)))"
],
"group_keys": []
},
{
"#operator": "FinalGroup",
"aggregates": [
"max(cover ((`travel-sample`.`city`)))"
],
"group_keys": []
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "max(cover ((`travel-sample`.`city`)))"
}
]
},
{
"#operator": "FinalProject"
}
]
}
}
]
},
"text": "SELECT MAX(city) \nFROM `travel-sample` \nuse index (def_city)\nWHERE city is not null;"
}MIN() Pushdown
(Introduced in Couchbase Server 5.0)
This function returns the lowest value of the input field based on the default collation rules (for details, see Data types and Comparison Operators)
MIN() can be pushed to the Indexer only when the index is created with matching index keys in ascending order.
In such cases, the minimum value will be the first entry in the Index when keys are in ascending order, so the N1QL engine will automatically add the hint Limit: 1 to the index scan.
In the EXPLAIN output of the query, you can see the limit hint.
Example 2: Uses the def_city index that comes pre-installed and can be made by the statement:
USE INDEX def_city ON `travel-sample`(city DESC);Example 2a: MIN of a string field – Finding the alphabetically lowest city name in travel-sample.
CREATE INDEX idx_city_asc ON `travel-sample`(city DESC);
EXPLAIN SELECT MIN(city)
FROM `travel-sample`
USE INDEX (def_city)
WHERE city is not null;Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"covers": [
"cover ((`travel-sample`.`city`))",
"cover ((meta(`travel-sample`).`id`))"
],
"index": "def_city",
"index_id": "e0a377e15a408175",
"index_projection": {
"entry_keys": [
0
]
},
"keyspace": "travel-sample",
"limit": "1", / this line is an added hint
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"inclusion": 0,
"low": "null"
}
]
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"maxParallelism": 1,
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Filter",
"condition": "(cover ((`travel-sample`.`city`)) is not null)"
},
{
"#operator": "InitialGroup",
"aggregates": [
"min(cover ((`travel-sample`.`city`)))"
],
"group_keys": []
}
]
}
},
{
"#operator": "IntermediateGroup",
"aggregates": [
"min(cover ((`travel-sample`.`city`)))"
],
"group_keys": []
},
{
"#operator": "FinalGroup",
"aggregates": [
"min(cover ((`travel-sample`.`city`)))"
],
"group_keys": []
},
{
"#operator": "Parallel",
"maxParallelism": 1,
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "min(cover ((`travel-sample`.`city`)))"
}
]
},
{
"#operator": "FinalProject"
}
]
}
}
]
},
"text": "SELECT MIN(city) \nFROM `travel-sample` \nuse index (def_city)\nWHERE city is not null;"
}COUNT() Pushdown
(Introduced in Couchbase Server 5.0)
This function returns the total number of non-Null values of an input field from the matching documents of an index scan.
As shown in Example 3b, the newly added index operator IndexCountScan2 counts values so the Query Service does not need to do additional processing.
Example 3: Uses the def_city index that comes pre-installed and can be made by the statement:
CREATE INDEX def_city ON `travel-sample`(city ASC);Example 3a: Count of a string field — Finding the number of cities entered in travel-sample.
SELECT COUNT(city) AS NumberOfCities
FROM `travel-sample`
use index (def_city)
WHERE city is not null;Result:
[
{
"NumberOfCities": 7341
}
]Example 3b: The details behind Example 3.
EXPLAIN SELECT COUNT(city) AS NumberOfCities
FROM `travel-sample`
use index (def_city)
WHERE city is not null;Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexCountScan2", / newly added
"covers": [
"cover ((`travel-sample`.`city`))",
"cover ((meta(`travel-sample`).`id`))"
],
"index": "def_city",
"index_id": "e0a377e15a408175",
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"inclusion": 0,
"low": "null"
}
]
}
],
"using": "gsi"
},
{
"#operator": "IndexCountProject",
"result_terms": [
{
"as": "NumberOfCities",
"expr": "count((`travel-sample`.`city`))"
}
]
}
]
},
"text": "SELECT COUNT(city) AS NumberOfCities\nFROM `travel-sample` \nuse index (def_city)\nWHERE city is not null;"
}COUNT(DISTINCT) Pushdown
(Introduced in Couchbase Server 5.0)
This function returns the total number of unique non-Null values of an input field from the matching documents of an index scan.
As shown in Example 4b, the newly added index operator IndexCountScan2 counts distinct values so the Query Service does not need to do additional processing.
Example 4: Uses the def_city index that comes pre-installed and can be made by the statement:
CREATE INDEX def_city ON `travel-sample`(city ASC);Example 4a: Count Distinct of a string field — Finding the number of unique city names in travel-sample.
SELECT COUNT (DISTINCT city) AS NumberOfDistinctCities
FROM `travel-sample`
USE index (def_city)
WHERE city is not null;Result:
[
{
"NumberOfDistinctCities": 2301
}
]Example 4b: The details behind Example 5.
EXPLAIN SELECT COUNT (DISTINCT city) AS NumberOfDistinctCities
FROM `travel-sample`
use index (def_city)Result:
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexCountDistinctScan2", / newly added operator
"covers": [
"cover ((`travel-sample`.`city`))",
"cover ((meta(`travel-sample`).`id`))"
],
"index": "def_city",
"index_id": "e0a377e15a408175",
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"inclusion": 0,
"low": "null"
}
]
}
],
"using": "gsi"
},
{
"#operator": "IndexCountProject",
"result_terms": [
{
"as": "NumberOfDistinctCities",
"expr": "count(distinct (`travel-sample`.`city`))"
}
]
}
]
},
"text": "SELECT COUNT (DISTINCT city) AS NumberOfDistinctCities\nFROM `travel-sample` \nuse index (def_city)\nWHERE city is not null;"
}