FROM clause
The FROM clause specifies the keyspaces and JOIN operations on them.
(Introduced in Couchbase Server 4.0)
Purpose
In a SELECT query or subquery, the FROM clause specifies one or more of the following:
-
Keyspaces
-
Subqueries (such as derived tables)
-
JOIN clauses
-
JOIN conditions
-
Expressions (nested collections,
CURL(), or other expressions)
Prerequisites
For you to select data from keyspace or expression, you must have the query_select privilege on that keyspace.
For more details about user roles, see
Authorization.
Syntax
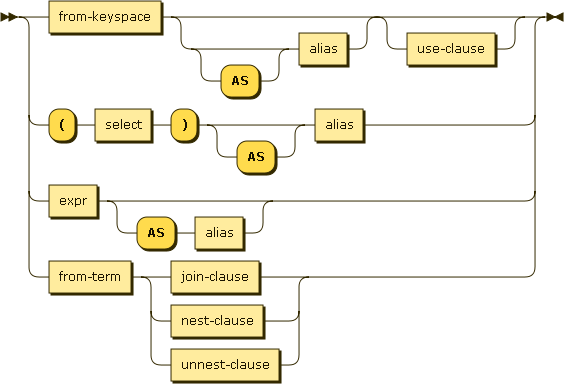
FROM from-keyspace [ [ AS ] alias1 ] [ USE KEYS use-clause ]
| "(" SELECT ")" [ [ AS ] alias2 ]
| expr [ [ AS ] alias3 ]
| from-term ( join-clause | nest-clause | unnest-clause )
| Argument / Clause | Description |
|---|---|
from-keyspace
|
Identifier that represents the keyspace for the query, such as
|
( select-expr ) |
To specify a N1QL SELECT subquery |
expr |
A N1QL expression generating JSON documents or objects. |
from-term
|
A N1QL expression that defines the input object(s) for the query, which can be either a keyspace identifier, generic expression, or subquery along with one or more JOIN, NEST, or UNNEST clause.
|
from-keyspace
You can specify a keyspace to query from, either a specific bucket or a constant expression.
If the from-keyspace clause is used, then there must be a from-keyspace-name specified.
The simplest type of from-keyspace clause specifies a single bucket (i.e., SELECT * FROM `travel-sample`).
Keyspace identifier is the name or identifier of an independent place for a data source of one or more documents. Such keyspaces are not dependent on any of the Variable in Scope of a Subquery.
from-keyspace Example: Use a keyspace from a single bucket.
Select four unique landmarks from the `travel-sample` bucket.
SELECT DISTINCT name FROM `travel-sample` WHERE type = "landmark" LIMIT 4;
Results:
[
{
"name": "Royal Engineers Museum"
},
{
"name": "Hollywood Bowl"
},
{
"name": "Thai Won Mien"
},
{
"name": "Spice Court"
}
]
N1QL Expressions in a FROM Clause
Couchbase Server version 4.6.2 added support for generic expressions in the from-term clause; and this adds huge flexibility by the enabling of various N1QL functions, operators, path expressions, language constructs on constant expressions, variables, and subqueries to create just about any FROM clause imaginable.
-
When the
from-termis an expression,USE KEYSorUSE INDEXclauses are not allowed. -
When using a
JOINclause,NESTclause, orUNNESTclause, the left-side keyspace can be an expression or subquery, but the right-side keyspace must be a keyspace identifier.- 1. Independent Constant Expression
-
This includes any N1QL expressions of JSON scalar values, static JSON literals, objects, or N1QL functions, for example:
SELECT * FROM [1, 2, "name", { "type" : "airport", "id" : "SFO"}] AS ks1; SELECT CURL("https://maps.googleapis.com/maps/api/geocode/json", {"data":"address=Half+Moon+Bay" , "request":"GET"} );Note that functions such as CURL() can independently produce input data objects for the query. Similarly, other N1QL functions can also be used in the expressions.
- 2. Variable N1QL Expression
-
This includes expressions that refer to any variables in scope for the query, for example:
SELECT count(*) FROM `travel-sample` t LET x = t.geo WHERE (SELECT RAW y.alt FROM x y)[0] > 6000;
The
FROM xclause is an expression that refers to the outer query. This is applicable to only subqueries because the outermost level query cannot use any variables in its ownFROMclause. This makes the subquery correlated with outer queries, as explained in the Subqueries section. - 3. Subquery and Subquery Expressions
-
Subquery Example: For each country, find the number of airports at different altitudes and their corresponding cities.
In this case, the inner query finds the first level of grouping of different altitudes by country and corresponding number of cities. Then the outer query builds on the inner query results to count the number of different altitude groups for each country and the total number of cities.
SELECT t1.country, num_alts, total_cities FROM (SELECT country, geo.alt AS alt, count(city) AS num_cities FROM `travel-sample` WHERE type = "airport" GROUP BY country, geo.alt) t1 GROUP BY t1.country LETTING num_alts = count(t1.alt), total_cities = sum(t1.num_cities);Results:
[ { "country": "United States", "num_alts": 946, "total_cities": 1560 }, { "country": "United Kingdom", "num_alts": 128, "total_cities": 187 }, { "country": "France", "num_alts": 196, "total_cities": 221 } ]This is equivalent to blending the results of the following two queries by country, but the subquery in the
from-termabove simplified it.SELECT country,count(city) AS num_cities FROM `travel-sample` WHERE type = "airport" GROUP BY country; SELECT country, count(distinct geo.alt) AS num_alts FROM `travel-sample` WHERE type = "airport" GROUP BY country;
For more details and examples, see Subqueries and ( select-expr ).
AS Alias
To use a shorter or clearer name anywhere in the query, like SQL, N1QL allows renaming fields by using the AS keyword to assign an alias to a keyspace or field in the FROM clause.
Syntax
[AS] alias
Arguments
AS-
[Optional] Reserved word denoting the next word is an alias of the previous term.
- alias
-
[Required if
ASis used] String to assign a name to a keyspace, such as the following equivalentFROMclauses with and without theASkeyword:FROM `travel-sample`AS tFROM `travel-sample`tFROM `travel-sample`AS hINNER JOIN `travel-sample`AS lON (h.city =l`.city)`FROM `travel-sample`hINNER JOIN `travel-sample`lON (h.city =l`.city)`Since the original name may lead to referencing wrong data and wrong results, you must use the alias name throughout the query instead of the original keyspace name.
In the FROM clause, the renaming appears only in the projection and not the fields themselves.
When no alias is used, the keyspace or last field name of an expression is given as the implicit alias.
When an alias conflicts with a keyspace or field name in the same scope, the identifier always refers to the alias. This allows for consistent behavior in scenarios where an identifier only conflicts in some documents. For more information on aliases, see Identifiers.
USE KEYS Clause
You can refer to a document’s unique document key by using the USE KEYS clause.
Only documents having those document keys will be included as inputs to a query.
Syntax

USE [ PRIMARY ] KEYS expr
- Arguments
-
- PRIMARY
-
[Optional]
USE KEYSandUSE PRIMARY KEYSare synonyms. - expr
-
String of a document key or an array of comma-separated document keys.
USE KEYS Example 1: Select a single document by its document key.
SELECT * FROM `travel-sample` USE KEYS "airport_1254";
Results:
[
{
"travel-sample": {
"airportname": "Calais Dunkerque",
"city": "Calais",
"country": "France",
"faa": "CQF",
"geo": {
"alt": 12,
"lat": 50.962097,
"lon": 1.954764
},
"icao": "LFAC",
"id": 1254,
"type": "airport",
"tz": "Europe/Paris"
}
}
]
USE KEYS Example 2: Select multiple documents by their document keys.
SELECT * FROM `travel-sample` USE KEYS ["airport_1254","airport_1255"];
Results:
[
{
"travel-sample": {
"airportname": "Calais Dunkerque",
"city": "Calais",
"country": "France",
"faa": "CQF",
"geo": {
"alt": 12,
"lat": 50.962097,
"lon": 1.954764
},
"icao": "LFAC",
"id": 1254,
"type": "airport",
"tz": "Europe/Paris"
}
},
{
"travel-sample": {
"airportname": "Peronne St Quentin",
"city": "Peronne",
"country": "France",
"faa": null,
"geo": {
"alt": 295,
"lat": 49.868547,
"lon": 3.029578
},
"icao": "LFAG",
"id": 1255,
"type": "airport",
"tz": "Europe/Paris"
}
}
]
( select-expr )
Use parenthesis to specify a N1QL SELECT expression of input objects.
Arguments
- select-expr
-
[Required] The N1QL
SELECTquery of input objects.
Example 1: A SELECT clause inside a FROM clause.
List all Gillingham landmark names from a subset of all landmark names and addresses.
SELECT name, city
FROM (SELECT id, name, address, city
FROM `travel-sample`
WHERE type = "landmark") as Landmark_Info
WHERE city = "Gillingham";
Results:
[
{
"city": "Gillingham",
"name": "Royal Engineers Museum"
},
{
"city": "Gillingham",
"name": "Hollywood Bowl"
},
{
"city": "Gillingham",
"name": "Thai Won Mien"
},
{
"city": "Gillingham",
"name": "Spice Court"
},
{
"city": "Gillingham",
"name": "Beijing Inn"
},
{
"city": "Gillingham",
"name": "Ossie's Fish and Chips"
}
]
For more details and examples, see SELECT Clause.
from-term
The from-term defines the input object(s) for the query, and it can be one of the following types:
| Type | Example |
|---|---|
|
|
|
|
|
|
|
For more details with examples, click the above links.
| Couchbase Server version 4.6.2 adds support for generic expression in the from-term. Prior Couchbase Server versions support only the other two types. |
ANSI JOIN Clause
(Introduced in Couchbase Server Enterprise Edition 5.5)
| ANSI JOIN (and ANSI NEST) clauses have much more flexible functionality than their earlier INDEX and LOOKUP equivalents. Since these are standard compliant and more flexible, we recommend you to use ANSI JOIN (and ANSI NEST) exclusively, where possible. |
Purpose
To be closer to standard SQL syntax, ANSI JOIN can join arbitrary fields of the documents and can be chained together.
The following table lists the JOIN types currently supported.
| Join Type | Remarks | Example |
|---|---|---|
[INNER] JOIN ... ON |
INNER JOIN and LEFT OUTER JOIN can be mixed in any number and/or order. |
|
LEFT [OUTER] JOIN ... ON |
|
|
RIGHT [OUTER] JOIN ... ON |
RIGHT OUTER JOIN can only be the first join specified in a FROM clause. |
|
Syntax

lhs-expr [join-type] JOIN rhs-expr ON join-clause
Arguments
- lhs-expr
-
[Required] Keyspace reference or expression representing the left-hand side of the join clause.
- join-type
-
[Optional. Default is
INNER] String representing the type of join.INNER-
[Optional. Default is
INNER]For each joined object produced, both the left-hand side and right-hand side source objects of the
ONclause must be non-MISSING and non-NULL. LEFT [OUTER]-
[Optional. Query Service interprets
LEFTasLEFT OUTER]For each joined object produced, only the left-hand source objects of the
ONclause must be non-MISSING and non-NULL RIGHT [OUTER]-
[Optional. Query Service interprets
RIGHTasRIGHT OUTER]For each joined object produced, only the right-hand source objects of the
ONclause must be non-MISSING and non-NULL
JOINrhs-expr-
[Required] Keyspace reference or expression representing the right-hand side of the join clause.
ONjoin-clause-
[Required] Boolean expression representing the join condition between the left-hand side expression and the right-hand side expression, which can be fields, constant expressions or any complex N1QL expression.
ANSI Join Example 1: Inner Join.
List the source airports and airlines that fly into SFO, where only the non-null route documents join with matching airline documents.
SELECT route.airlineid, airline.name, route.sourceairport, route.destinationairport FROM `travel-sample` route INNER JOIN `travel-sample` airline ON route.airlineid = META(airline).id WHERE route.type = "route" AND route.destinationairport = "SFO" ORDER BY route.sourceairport;
Results:
[
{
"airlineid": "airline_5209",
"destinationairport": "SFO",
"name": "United Airlines",
"sourceairport": "ABQ"
},
{
"airlineid": "airline_5209",
"destinationairport": "SFO",
"name": "United Airlines",
"sourceairport": "ACV"
},
{
"airlineid": "airline_5209",
"destinationairport": "SFO",
"name": "United Airlines",
"sourceairport": "AKL"
},
...
ANSI Join Example 2: Left Outer Join of U.S. airports in the same city as a landmark.
List the airports and landmarks in the same city, ordered by the airports.
SELECT DISTINCT MIN(aport.airportname) AS Airport__Name,
MIN(lmark.name) AS Landmark_Name,
MIN(aport.tz) AS Landmark_Time
FROM `travel-sample` aport
LEFT JOIN `travel-sample` lmark
ON aport.city = lmark.city
AND lmark.country = "United States"
AND lmark.type = "landmark"
WHERE aport.type = "airport"
GROUP BY lmark.name
ORDER BY lmark.name;
Results:
[
{
"Airport__Name": "San Francisco Intl",
"Landmark_Name": ""Hippie Temptation" house",
"Landmark_Time": "America/Los_Angeles"
},
{
"Airport__Name": "Los Angeles Intl",
"Landmark_Name": "101 Coffee Shop",
"Landmark_Time": "America/Los_Angeles"
},
{
"Airport__Name": "San Francisco Intl",
"Landmark_Name": "1015",
"Landmark_Time": "America/Los_Angeles"
},
{
"Airport__Name": "San Francisco Intl",
"Landmark_Name": "1235 Masonic Ave",
"Landmark_Time": "America/Los_Angeles"
},
...
ANSI Join Example 3: RIGHT OUTER JOIN of Example #2.
List the airports and landmarks in the same city, ordered by the landmarks.
| The LEFT OUTER JOIN will list all left-side results regardless of matching right-side documents; while the RIGHT OUTER JOIN will list all right-side results regardless of matching left-side documents. |
SELECT DISTINCT MIN(aport.airportname) AS Airport_Name,
MIN(lmark.name) AS Landmark_Name,
MIN(aport.tz) AS Landmark_Time
FROM `travel-sample` aport
RIGHT JOIN `travel-sample` lmark
ON aport.city = lmark.city
AND aport.type = "airport"
AND aport.country = "United States"
WHERE lmark.type = "landmark"
GROUP BY lmark.name
ORDER BY lmark.name;
Results:
[
{
"Airport_Name": "San Francisco Intl",
"Landmark_Name": ""Hippie Temptation" house",
"Landmark_Time": "America/Los_Angeles"
},
{
"Airport_Name": "London-Corbin Airport-MaGee Field",
"Landmark_Name": "02 Shepherd's Bush Empire",
"Landmark_Time": "America/New_York"
},
{
"Airport_Name": "Los Angeles Intl",
"Landmark_Name": "101 Coffee Shop",
"Landmark_Time": "America/Los_Angeles"
},
{
"Airport_Name": "San Francisco Intl",
"Landmark_Name": "1015",
"Landmark_Time": "America/Los_Angeles"
},
...
ANSI Join Example #4: In the `beer-sample` bucket, use an ANSI JOIN to list the beer names and breweries that are in the state Wisconsin (WI).
First, create an index with beer.brewry_id as the leading key.
CREATE INDEX beer_brewery ON `beer-sample` (brewery_id)
WHERE type = "beer"
SELECT META(brewery).id bid, META(beer).id, brewery.name brewery_name,
beer.name beer_name
FROM `beer-sample` brewery
JOIN `beer-sample` beer
ON beer.brewery_id = LOWER(REPLACE(brewery.name, " ", "_"))
WHERE beer.type = "beer"
AND brewery.type = "brewery"
AND brewery.state = "WI";
Results:
[
{
"beer_name": "Dank",
"bid": "oso",
"brewery_name": "Oso",
"id": "oso-dank"
}
]
Visual Explain Plan: 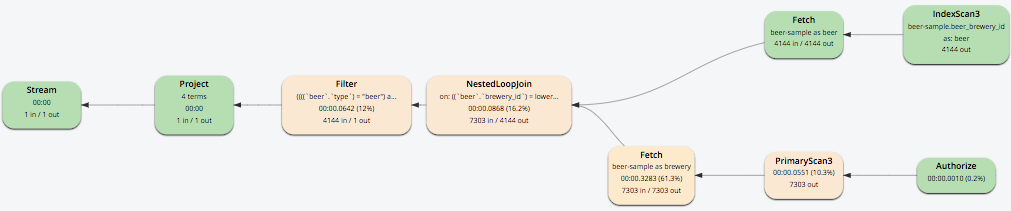
If you add name as the second index key to the beer_brewery index:
CREATE INDEX beer_brewery_name ON `beer-sample` (brewery_id, name) WHERE type = "beer"
... then you will get covering index scan, as shown in the Visual Explain Plan:
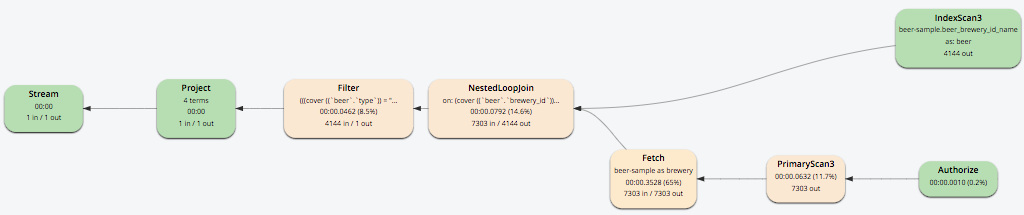
Limitations
The following Join types are currently not supported:
-
RIGHT OUTER JOINis only supported when it’s the only join in the query; or in a chain of joins, theRIGHT OUTER JOINmust be the first join in the chain. -
No mixing of new ANSI Join syntax with Lookup/Index Join syntax in the same FROM clause.
-
The right-hand-side of any join must be a keyspace. Expressions, subqueries, or other join combinations cannot be on the right-hand-side of a join.
-
A join can only be executed when appropriate index exists on the inner side of the join.
-
Adaptive indexes are not considered when selecting indexes on inner side of the join.
ANSI JOIN Hints (HASH & NL)
(Introduced in Couchbase Server Enterprise Edition 5.5)
Couchbase Server Enterprise Edition supports two join methods for performing ANSI Join: nested-loop join and hash join.
The default join method is nested-loop join.
Two corresponding join hints are introduced: USE HASH and USE NL.
Hash join is only considered when the USE HASH hint is specified, and it requires at least one equality predicate between the left-hand side and right-hand side.
In such cases, if a hash join is chosen successfully, then that’ll be the join method used for this join.
If the hash join cannot be generated, then the planner will further consider nested-loop join and will either generate a nested-loop join or return an error for the join.
If no join hint is specified or USE NL hint is specified, then nested-loop join is considered.
For Community Edition (CE), any specified USE HASH hint will be silently ignored and only nested-loop join is considered by the planner.
|
USE HASH hint
The USE HASH hint is similar to the existing USE INDEX or USE KEYS hint in that the USE HASH hint can be specified after a keyspace reference in an ANSI Join specification.
There are two versions of the USE HASH hint that indicate whether the keyspace is to be used as:
-
The build side of the hash join —
USE HASH(build) -
The probe side of the hash join —
USE HASH(probe)
A hash join has two sides: a BUILD and a PROBE.
The BUILD side of the join will be used to create an in-memory hash table.
The PROBE side will use that table to find matches and perform the join.
Typically, this means you want the BUILD side to be used on the smaller of the two sets.
However, you can only supply one hash hint, and only to the right side of the join.
So if you specify BUILD on the right side, then you are implicitly using PROBE on the left side (and vice versa).
USE HASH Example 1: PROBE
The keyspace aline is to be joined (with rte) using hash join, and aline is used as the probe side of the hash join.
SELECT COUNT(1) AS Total_Count FROM `travel-sample` rte INNER JOIN `travel-sample` aline USE HASH (PROBE) ON (rte.airlineid = META(aline).id) WHERE rte.type = "route";
Results:
[
{
"Total_Count": 17629
}
]
USE HASH Example 2: BUILD
This is effectively the same query as the previous example, except the two keyspaces are switched, and here the USE HASH(BUILD) hint is used, indicating the hash join should use rte as the build side.
SELECT COUNT(1) AS Total_Count FROM `travel-sample` aline INNER JOIN `travel-sample` rte USE HASH (BUILD) ON (rte.airlineid = META(aline).id) WHERE rte.type = "route";
Results:
[
{
"Total_Count": 17629
}
]
USE NL hint
This join hint instructs the planner to use nested-loop join (NL join) for the join being considered.
Since nested-loop join is the default path, the USE NL hint is not required.
USE NL Example:
SELECT COUNT(1) AS Total_Count FROM `travel-sample` rte INNER JOIN `travel-sample` aline USE NL ON (rte.airlineid = META(aline).id) WHERE rte.type = "route";
| The join hint for the first join should be specified on the 2nd keyspace reference, and the join hint for the second join should be specified on the 3rd keyspace reference, etc. If a join hint is specified on the first keyspace, an error is returned. |
Multiple hints
You can use only one join hint (USE HASH or USE NL) together with only one other hint (USE INDEX or USE KEYS) for a total of two hints. The order of the two hints doesn’t matter.
When multiple hints are being specified, use only one USE keyword with one following the other, as in the following examples.
Multiple hint Example 1: USE INDEX with USE HASH.
SELECT COUNT(1) AS Total_Count FROM `travel-sample` rte INNER JOIN `travel-sample` aline USE INDEX idx1 HASH (PROBE) ON (rte.airlineid = META(aline).id) WHERE rte.type = "route";
Multiple hint Example 2: USE HASH with USE KEYS.
SELECT COUNT(1) AS Total_Count FROM `travel-sample` rte INNER JOIN `travel-sample` aline USE HASH (PROBE) KEYS ["airline_key1", "airline_key2", "airline_key3"] ON (rte.airlineid = META(aline).id) WHERE rte.type = "route";
When chosen, the hash join will always work; the restrictions are on any USE KEYS hint clause:
-
Must not depend on any previous keyspaces.
-
The expression must be constants, host variables, etc.
-
Must not contain any subqueries.
| If the USE KEYS hint contains references to other keyspaces or subqueries, then the USE HASH hint will be ignored and nested-loop join will be used instead. |
ANSI JOIN and Arrays
ANSI JOIN provides great flexibility since the ON clause of an ANSI JOIN can be any expression as long as it evaluates to TRUE or FALSE.
Below are different join scenarios involving arrays and ways to handle each scenario.
|
These buckets and indexes will be used throughout this section’s array scenarios.
As a convention, when a field name starts with
|
ANSI JOIN with no arrays
In this scenario, there is no involvement of arrays in the join. These are just straight-forward joins:
SELECT * FROM b1 JOIN b2 ON b1.c11 = b2.c21 AND b2.c22 = 100 WHERE b1.c12 = 10;
Here the joins are using non-array fields of each keyspace.
The following case also falls in this scenario:
SELECT * FROM b1 JOIN b2 ON b1.c11 = b2.c21 AND b2.c22 = 100 AND ANY v IN b2.a21 SATISFIES v = 10 END WHERE b1.c12 = 10;
In this example, although there is an ANY predicate on the right-hand side array b2.a21, the ANY predicate does not involve any joins, and thus, as far as the join is concerned, it is still a 1-to-1 join.
Similarly:
SELECT * FROM b1 JOIN b2 ON b1.c11 = b2.c21 WHERE b1.c11 = 10 AND b1.c12 = 100 AND ANY v IN b1.a11 SATISFIES v = 20 END;
In this case the ANY predicate is on the left-hand side array b1.a11; however, similar to above, the ANY predicate does not involve any joins, and thus the join is still 1-to-1.
We can even have ANY predicates on both sides:
SELECT * FROM b1 JOIN b2 ON b1.c11 = b2.c21 AND b2.c22 = 100 AND ANY v IN b2.a21 SATISFIES v = 10 END WHERE b1.c11 = 10 AND b1.c12 = 100 AND ANY v IN b1.a11 SATISFIES v = 10 END;
Again, the ANY predicates do not involve any join, and the join is still 1-to-1.
ANSI JOIN with entire array as index key
As a special case, it is possible to perform ANSI JOIN on an entire array as a join key:
SELECT * FROM b1 JOIN b2 ON b1.a21 = b2.a22 WHERE b1.c11 = 10 AND b1.c12 = 100;
In this case, the entire array must match each other for the join to work.
For all practical purposes, the array here is treated as a scalar since there is no logic to iterate through elements of an array here.
The entire array is used as an index key (b2_idx2) and as such, an entire array is used as an index span to probe the index.
The join here can also be considered as 1-to-1.
ANSI JOIN involving right-hand-side arrays
In this scenario, the join involves an array on the right-hand side keyspace:
SELECT * FROM b1 JOIN b2 ON b2.c21 = 10 AND b2.c22 = 100 AND ANY v IN b2.a21 SATISFIES v = b1.c12 END WHERE b1.c11 = 10;
In this case, the ANY predicate involves a join, and thus, effectively we are joining b1 with elements of the b2.a21 array.
This now becomes a 1-to-many join.
Note that we use an ANY clause for this scenario since it’s a natural extension of the existing support for array indexes; the only difference is for index span generation, we now can have a potential join expression.
Array indexes can be used for join in this scenario.
ANSI JOIN involving left-hand-side arrays
This is a slightly more complex scenario, where the array reference is on the left-hand side of the join, and it’s a many-to-1 join. There are two alternative ways to handle the scenario where the array appears on the left-hand side of the join.
- Alternative #1: use UNNEST
-
This alternative will flatten the left-hand side array first, before performing the join:
SELECT * FROM b1 UNNEST b1.a12 AS ba1 JOIN b2 ON ba1 = b2.c22 AND b2.c21 = 10 WHERE b1.c11 = 10 AND b1.c12 = 100;
The UNNEST operation is used to flatten the array, turning one left-hand side document into multiple documents; and then for each one of them, join with the right-hand side. This way, by the time join is being performed, it is a regular join, since the array is already flattened in the UNNEST step.
- Alternative #2: use IN clause
-
This alternative uses the IN clause to handle the array:
SELECT * FROM b1 JOIN b2 ON b2.c22 IN b1.a12 AND b2.c21 = 10 WHERE b1.c11 = 10 AND b1.c12 = 100;
By using the IN clause, the right-hand side field value can match any of the elements of the left-hand side array. Conceptually, we are using each element of the left-hand side array to probe the right-hand side index.
- Differences between the two alternatives
-
There is a semantical difference between the two alternatives. With UNNEST, we are first turning one left-hand side document into multiple documents and then performing the join. With IN-clause, there is still only one left-hand side document, which can then join with one or more right-hand side documents. Thus:
-
If the array contains duplicate values,
-
the UNNEST method treats each duplicate as an individual value and thus duplicated results will be returned;
-
the IN clause method will not duplicate the result.
-
-
If no duplicate values exists and we are performing inner join,
-
then the two alternatives will likely give the same result.
-
-
If outer join is performed, assuming there are N elements in the left-hand side array, and assuming there is at most one matching document from the right-hand side for each element of the array,
-
the UNNEST method will produce N result documents;
-
the IN clause method may produce < N result documents if some of the array elements do not have matching right-hand side documents.
-
-
ANSI JOIN with arrays on both sides
If the join involves arrays on both sides, then we can combine the approaches above, i.e., using ANY clause to handle the right-hand side array and either UNNEST or IN clause to handle the left-hand side array. For example:
SELECT *
FROM b1
UNNEST b1.a12 AS ba1
JOIN b2
ON ANY v IN b2.a21 SATISFIES v = ba1 END
AND b2.c21 = 10
AND b2.c22 = 100
WHERE b1.c11 = 10
AND b1.c12 = 100;
or
SELECT * FROM b1 JOIN b2 ON ANY v IN b2.a21 SATISFIES v IN b1.a12 END AND b2.c21 = 10 AND b2.c22 = 100 WHERE b1.c11 = 10 AND b1.c12 = 100;
Lookup JOIN Clause
(Introduced in Couchbase Server 4.0)
The JOIN clause enables you to create new input objects by combining two or more source objects.
Lookup joins allow only left-to-right joins, which means the ON KEYS expression must produce a document key which is then used to retrieve documents from the right-hand side keyspace. Couchbase Server version 4.1 and earlier supported only lookup joins.
Syntax

[ join-type ] JOIN from-path [ [ AS ] alias ] ON KEYS on-keys-clause
- Arguments
-
- join-type
-
[Optional; default is
INNER]INNER-
For each joined object produced, both the left-hand and right-hand source objects must be non-
MISSINGand non-NULL. LEFT OUTER-
For each joined object produced, only the left-hand source objects must be non-
MISSINGand non-NULL.
- from-path
-
[Required] Keyspace reference for right-hand side of lookup join. For details, see Keyspaces.
- alias (Optionally,
ASalias) -
[Optional] To assign another name. For details, see AS Keyword.
ON KEYSon-keys-clause-
[Required] String or expression representing the primary keys of the documents for the right-hand side keyspace.
The
ON KEYSexpression produces one or more document keys for the right-hand side document.The
ON KEYSexpression can produce an array of document keys.
- Return Values
-
If
LEFTorLEFT OUTERis specified, then a left outer join is performed.At least one joined object is produced for each left-hand source object.
If the right-hand source object is
NULLorMISSING, then the joined object’s right-hand side value is alsoNULLorMISSING(omitted), respectively. - Limitations
-
Lookup JOINs can be chained with other lookup joins/nests or index joins/nests, but they cannot be mixed with an ANSI JOIN or ANSI NEST.
Lookup JOIN Example 1: route JOIN airline ON KEYS route.airlineid.
List all airlines and non-stop routes from SFO in the travel-sample keyspace.
SELECT DISTINCT airline.name, airline.callsign, route.destinationairport, route.stops, route.airline FROM `travel-sample` route JOIN `travel-sample` airline ON KEYS route.airlineid WHERE route.type = "route" AND airline.type = "airline" AND route.sourceairport = "SFO" AND route.stops = 0 LIMIT 4;
Results:
[
{
"airline": "VX",
"callsign": "REDWOOD",
"destinationairport": "SAN",
"name": "Virgin America",
"stops": 0
},
{
"airline": "VX",
"callsign": "REDWOOD",
"destinationairport": "PHL",
"name": "Virgin America",
"stops": 0
},
{
"airline": "B6",
"callsign": "JETBLUE",
"destinationairport": "FLL",
"name": "JetBlue Airways",
"stops": 0
},
{
"airline": "UA",
"callsign": "UNITED",
"destinationairport": "IND",
"name": "United Airlines",
"stops": 0
}
]
Lookup JOIN Example 2: route JOIN airline ON KEYS route.airlineid.
List the schedule of flights from Boston to San Francisco on JETBLUE in the travel-sample keyspace.
SELECT DISTINCT airline.name, route.schedule FROM `travel-sample` route JOIN `travel-sample` airline ON KEYS route.airlineid WHERE route.type = "route" AND airline.type = "airline" AND route.sourceairport = "BOS" AND route.destinationairport = "SFO" AND airline.callsign = "JETBLUE";
Results:
[
{
"name": "JetBlue Airways",
"schedule": [
{
"day": 0,
"flight": "B6076",
"utc": "10:15:00"
},
{
"day": 0,
"flight": "B6321",
"utc": "00:06:00"
},
{
"day": 1,
"flight": "B6536",
"utc": "22:45:00"
},
{
"day": 1,
"flight": "B6194",
"utc": "00:51:00"
},
{
"day": 2,
"flight": "B6918",
"utc": "23:45:00"
},
{
"day": 2,
"flight": "B6451",
"utc": "18:09:00"
},
{
"day": 2,
"flight": "B6868",
"utc": "22:04:00"
},
{
"day": 2,
"flight": "B6621",
"utc": "11:04:00"
},
{
"day": 3,
"flight": "B6015",
"utc": "16:59:00"
},
{
"day": 3,
"flight": "B6668",
"utc": "07:22:00"
},
{
"day": 3,
"flight": "B6188",
"utc": "01:41:00"
},
{
"day": 3,
"flight": "B6215",
"utc": "19:35:00"
},
{
"day": 4,
"flight": "B6371",
"utc": "21:37:00"
},
{
"day": 4,
"flight": "B6024",
"utc": "10:24:00"
},
{
"day": 4,
"flight": "B6749",
"utc": "01:12:00"
},
{
"day": 4,
"flight": "B6170",
"utc": "01:14:00"
},
{
"day": 5,
"flight": "B6613",
"utc": "08:59:00"
},
{
"day": 5,
"flight": "B6761",
"utc": "15:24:00"
},
{
"day": 5,
"flight": "B6162",
"utc": "02:42:00"
},
{
"day": 5,
"flight": "B6341",
"utc": "21:26:00"
},
{
"day": 5,
"flight": "B6347",
"utc": "08:43:00"
},
{
"day": 6,
"flight": "B6481",
"utc": "22:08:00"
},
{
"day": 6,
"flight": "B6549",
"utc": "21:48:00"
},
{
"day": 6,
"flight": "B6994",
"utc": "11:30:00"
},
{
"day": 6,
"flight": "B6892",
"utc": "13:27:00"
}
]
}
]
Index JOIN Clause
(Introduced in Couchbase Server 4.0)
When Lookup JOINs cannot efficiently join left-hand side documents with right-to-left joins and your situation cannot be flipped because your predicate needs to be on the left-hand side (such as the above Lookup Example #1 where airline documents have no reference to route documents), then Index JOINs can be used efficiently without making a Cartesian product of all route documents. Index JOINs allow you to flip the direction of your join clause.
Consider the below query similar to the above Lookup Example #1 with route and airline documents where route.airlineid is the document key of route documents and airline documents have no reference to route documents:
SELECT DISTINCT airline.name, airline.callsign, route.destinationairport, route.stops, route.airline FROM `travel-sample` route JOIN `travel-sample` airline ON KEYS route.airlineid WHERE route.type = "route" AND airline.type = "airline" AND airline.icao = "SEA" LIMIT 4;
This query gets a list of Seattle (SEA) flights, but getting SEA flights cannot be efficiently executed without making a Cartesian product of all route documents (LHS) with all airline documents (RHS).
This query cannot use any index on airline to directly access SEA flights because airline is on the RHS.
Also, you cannot rewrite the query to put the airline document on the LHS (to use any index) and the route document on the RHS because the airline documents (on the LHS) have no primary keys to access the route documents (on the RHS).
Using index joins, the same query can be written as:
Required Index:
CREATE INDEX route_airlineid ON `travel-sample`(airlineid) WHERE type="route";
Optional index:
CREATE INDEX airline_icao ON `travel-sample`(icao) WHERE type="airline";
Resulting in:
SELECT * FROM `travel-sample` airline
JOIN `travel-sample` route
ON KEY route.airlineid FOR airline
WHERE route.type="route"
AND airline.type="airline"
AND airline.icao = "SEA";
If you generalize the same query, it looks like the following:
CREATE INDEX on-key-for-index-name rhs-expression (lhs-expression-key); SELECT projection-list FROM lhs-expression JOIN rhs-expression ON KEY rhs-expression.lhs-expression-key FOR lhs-expression [ WHERE predicates ] ;
There are three important changes in the index scan syntax example above:
-
CREATE INDEXon theON KEYexpressionroute.airlineidto accessroutedocuments usingairlineid(which are produced on the LHS). -
The
ON KEY route.airlineid FOR airlineenables N1QL to use the indexroute.airlineid. -
Create any optional index such as
route.airlinethat can be used on airline (LHS).
For index joins, the syntax uses ON KEY (singular) instead of ON KEYS (plural).
This is because Index JOINs' ON KEY expression must produce a scalar value; whereas Lookup JOINs' ON KEYS expression can produce either a scalar or an array value.
|
Syntax

[ join-type ] JOIN from-path [ [ AS ] alias ] ON KEY FOR on-key-for-clause
- Arguments
-
- join-type
-
[Optional; default is
LEFT INNER]LEFTorLEFT INNER-
For each joined object produced, both the left-hand and right-hand source objects must be non-
MISSINGand non-NULL. LEFT OUTER-
For each joined object produced, only the left-hand source objects must be non-
MISSINGand non-NULL.
- from-path
-
Keyspace reference for right-hand side of an index join. For details, see Keyspaces.
ASalias-
[Optional] To assign another name. For details, see AS Keyword.
ON KEYrhs-expression.lhs-expression-key-
- rhs-expression
-
Keyspace reference for the right-hand side of the index join.
- lhs-expression-key
-
String or expression representing the attribute in rhs-expression referencing the document key for lhs-expression.
- FOR lhs-expression
-
Keyspace reference for the left-hand side of the index join.
Index JOIN Example 1:ON KEY ... FOR.
The following example counts the number of distinct "AA" airline routes for each airport after creating the following index (if not already created).
CREATE INDEX route_airlineid ON `travel-sample`(airlineid) WHERE type="route"; SELECT Count(DISTINCT route.sourceairport) AS DistinctAirports FROM `travel-sample` airline JOIN `travel-sample` route ON KEY route.airlineid FOR airline WHERE route.type = "route" AND airline.type = "airline" AND airline.iata = "AA";
Results:
[
{
"DistinctAirports": 429
}
]
UNNEST Clause
If a document or object contains a nested array, UNNEST conceptually performs a join of the nested array with its parent object. Each resulting joined object becomes an output of the query. Unnests can be chained.
Syntax

[ join-type ] UNNEST path [ [ AS ] alias ]
- Arguments
-
- join-type
-
[Optional; default is
INNER]INNER-
For each result object produced, the array object in the left-hand side keyspace must be non-empty.
LEFTorLEFT OUTER-
A left-outer unnest is performed, and at least one result object is produced for each left source object.
- path
-
[Required] The first path element after each UNNEST must reference some preceding path.
- alias (optionally,
ASalias) -
[Required] To assign a name for the unnested item. For details, see AS Keyword.
- Return Values
-
If the right-hand source object is
NULL,MISSING, empty, or a non-array value, then the result object’s right-side value isMISSING(omitted).
UNNEST Example 1: UNNEST an array to select an item.
In the travel-sample keyspace, flatten the schedule array to get a list of the flights on Monday (1).
SELECT sched FROM `travel-sample` UNNEST schedule sched WHERE sched.day = 1 LIMIT 3;
Results :
[
{
"sched": {
"day": 1,
"flight": "AF356",
"utc": "12:40:00"
}
},
{
"sched": {
"day": 1,
"flight": "AF480",
"utc": "08:58:00"
}
},
{
"sched": {
"day": 1,
"flight": "AF250",
"utc": "12:59:00"
}
}
]
Another way to get similar results is by using a Collection Operator to find array items that meet our criteria:
SELECT ARRAY item FOR item IN schedule WHEN item.day = 1 END AS Monday_flights FROM `travel-sample` WHERE type = "route" AND ANY item IN schedule SATISFIES item.day = 1 END LIMIT 3;
However, without the UNNEST clause, the unflattened list results in 3 sets of flights instead of only 3 individual flights:
[
{
"Monday_flights": [
{
"day": 1,
"flight": "AF356",
"utc": "12:40:00"
},
{
"day": 1,
"flight": "AF480",
"utc": "08:58:00"
},
{
"day": 1,
"flight": "AF250",
"utc": "12:59:00"
},
{
"day": 1,
"flight": "AF130",
"utc": "04:45:00"
}
]
},
{
"Monday_flights": [
{
"day": 1,
"flight": "AF517",
"utc": "13:36:00"
},
{
"day": 1,
"flight": "AF279",
"utc": "21:35:00"
},
{
"day": 1,
"flight": "AF753",
"utc": "00:54:00"
},
{
"day": 1,
"flight": "AF079",
"utc": "15:29:00"
},
{
"day": 1,
"flight": "AF756",
"utc": "06:16:00"
}
]
},
{
"Monday_flights": [
{
"day": 1,
"flight": "AF975",
"utc": "11:23:00"
},
{
"day": 1,
"flight": "AF225",
"utc": "16:05:00"
}
]
}
]
UNNEST Example 2: Use UNNEST to collect items from one array to use in another query.
In this example, the UNNEST clause iterates over the reviews array and collects the author names of the reviewers who rated the rooms less than a 2 to be contacted for ways to improve.
r is an element of the array generated by the UNNEST operation.
SELECT RAW r.author FROM `travel-sample` UNNEST reviews AS r WHERE `travel-sample`.type = "hotel" AND r.ratings.Rooms < 2 LIMIT 4;
This results in:
[ "Kayli Cronin", "Shanelle Streich", "Catharine Funk", "Tyson Beatty" ]
ANSI NEST Clause
(Introduced in Couchbase Server Enterprise Edition 5.5)
| ANSI NEST (and ANSI JOIN) clauses are much faster and have much more flexible functionality than their earlier INDEX and LOOKUP equivalents, so users are strongly recommended to use ANSI NEST (and ANSI JOIN) exclusively, where possible. |
ANSI NEST supports more nest types than Couchbase Server version 4.0’s NEST was able. ANSI NEST can nest arbitrary fields of the documents and can be chained together.
The key difference between the currently supported nests and ANSI NEST support is the replacement of the current ON KEYS or ON KEY … FOR clauses with a simple ON clause.
The ON KEYS or ON KEY … FOR clauses dictate that those nests can only be done on a document key (primary key for a document).
The ON clause can contain any expression, and thus it opens up many more nest possibilities that Couchbase did not previously support.
Syntax

lhs-expr [ nest-type] NESTrhs-expr ON nest-clause
Arguments
- lhs-expr
-
[Required] Keyspace reference or expression representing the left-hand side of the nest clause.
- nest-type
-
[Optional. Default is
INNER] String representing the type of nest.INNER-
[Optional. Default is
INNER]For each nested object produced, both the left-hand and right-hand source objects must be non-MISSING and non-NULL.
LEFT [OUTER]-
[Optional. Query Service interprets
LEFTasLEFT OUTER]For each nested object produced, only the left-hand source objects must be non-MISSING and non-NULL.
NESTrhs-expr-
[Required] Keyspace reference or expression representing the right-hand side of the nest clause.
ONnest-clause-
[Required] Boolean expression representing the nest condition between the left-hand side expression and the right-hand side expression, which can be fields, constant expressions or any complex N1QL expression.
Limitations
The following nest types are currently not supported:
-
Full OUTER NEST
-
Cross NEST
-
No mixing of new ANSI NEST syntax with NEST syntax in the same FROM clause.
-
The right-hand-side of any nest must be a keyspace. Expressions, subqueries, or other join combinations cannot be on the right-hand-side of a nest.
-
A nest can only be executed when appropriate index exists on the inner side of the ANSI NEST (similar to current NEST support).
-
Adaptive indexes are not considered when selecting indexes on inner side of the nest
ANSI NEST Example 1: Inner ANSI NEST
List the airlines, their plane model (equipment), and number of stops for flights between San Francisco and Boston.
SELECT r.airline, r.equipment, r.stops FROM `travel-sample` r NEST `travel-sample` a ON r.airlineid = META(a).id WHERE r.sourceairport = "SFO" AND r.destinationairport = "BOS";
Results:
[
{
"airline": "B6",
"equipment": "320",
"stops": 0
},
{
"airline": "UA",
"equipment": "752 753 738 739 319 320",
"stops": 0
},
{
"airline": "VX",
"equipment": "320",
"stops": 0
}
]
Lookup NEST Clause
(Introduced in Couchbase Server 4.0)
Nesting is conceptually the inverse of unnesting. Nesting performs a join across two keyspaces. But instead of producing a cross-product of the left and right inputs, a single result is produced for each left input, while the corresponding right inputs are collected into an array and nested as a single array-valued field in the result object.
Syntax

[ join-type ] NEST from-path [ [ AS ] alias ] on-keys-clause
- Arguments
-
- join-type
-
[Optional; default is
INNER]INNER-
For each result object produced, both the left-hand and right-hand source objects must be non-
MISSINGand non-NULL. LEFTorLEFT OUTER-
A left-outer unnest is performed, and at least one result object is produced for each left source object.
For each joined object produced, only the left-hand source objects must be non-
MISSINGand non-NULL.
- from-path
-
[Required] Keyspace reference for right-hand side of lookup nest. For details, see Keyspaces.
- alias (optionally,
ASalias) -
[Required] To assign a name for the right-hand side keyspace. For details, see AS Keyword.
- on-keys-clause
-
[Required] String or expression representing the primary keys of the documents for the second keyspace.
The
ON KEYSexpression produces one or more document keys for the right-hand side document.The
ON KEYSexpression can produce an array of document keys.
- Return Values
-
If the right-hand source object is NULL, MISSING, empty, or a non-array value, then the result object’s right-side value is MISSING (omitted).
Nests can be chained with other NEST, JOIN, and UNNEST clauses. By default, an INNER NEST is performed. This means that for each result object produced, both the left and right source objects must be non-missing and non-null. The right-hand side result of NEST is always an array or MISSING. If there is no matching right source object, then the right source object is as follows:
If the ON KEYSexpression evaluates toThen the right-side value is MISSINGMISSINGNULLMISSINGan array
an empty array
a non-array value
an empty array
Lookup NEST Example 1: Join two keyspaces producing an output for each left input.
Show one set of routes for one airline in the travel-sample keyspace.
SELECT * FROM `travel-sample` route INNER NEST `travel-sample` airline ON KEYS route.airlineid WHERE route.type = "route" LIMIT 1;
Results:
[
{
"airline": [
{
"callsign": "AIRFRANS",
"country": "France",
"iata": "AF",
"icao": "AFR",
"id": 137,
"name": "Air France",
"type": "airline"
}
],
"route": {
"airline": "AF",
"airlineid": "airline_137",
"destinationairport": "MRS",
"distance": 2881.617376098415,
"equipment": "320",
"id": 10000,
"schedule": [
{
"day": 0,
"flight": "AF198",
"utc": "10:13:00"
},
{
"day": 0,
"flight": "AF547",
"utc": "19:14:00"
},
{
"day": 0,
"flight": "AF943",
"utc": "01:31:00"
},
{
"day": 1,
"flight": "AF356",
"utc": "12:40:00"
},
{
"day": 1,
"flight": "AF480",
"utc": "08:58:00"
},
{
"day": 1,
"flight": "AF250",
"utc": "12:59:00"
},
{
"day": 1,
"flight": "AF130",
"utc": "04:45:00"
},
{
"day": 2,
"flight": "AF997",
"utc": "00:31:00"
},
{
"day": 2,
"flight": "AF223",
"utc": "19:41:00"
},
{
"day": 2,
"flight": "AF890",
"utc": "15:14:00"
},
{
"day": 2,
"flight": "AF399",
"utc": "00:30:00"
},
{
"day": 2,
"flight": "AF328",
"utc": "16:18:00"
},
{
"day": 3,
"flight": "AF074",
"utc": "23:50:00"
},
{
"day": 3,
"flight": "AF556",
"utc": "11:33:00"
},
{
"day": 4,
"flight": "AF064",
"utc": "13:23:00"
},
{
"day": 4,
"flight": "AF596",
"utc": "12:09:00"
},
{
"day": 4,
"flight": "AF818",
"utc": "08:02:00"
},
{
"day": 5,
"flight": "AF967",
"utc": "11:33:00"
},
{
"day": 5,
"flight": "AF730",
"utc": "19:42:00"
},
{
"day": 6,
"flight": "AF882",
"utc": "17:07:00"
},
{
"day": 6,
"flight": "AF485",
"utc": "17:03:00"
},
{
"day": 6,
"flight": "AF898",
"utc": "10:01:00"
},
{
"day": 6,
"flight": "AF496",
"utc": "07:00:00"
}
],
"sourceairport": "TLV",
"stops": 0,
"type": "route"
}
}
]
Index NEST Clause
(Introduced in Couchbase Server 4.0)
When Lookup NESTs cannot efficiently nest left-hand side documents with right-to-left nests and your situation cannot be flipped because your predicate needs to be on the left-hand side (such as the above Lookup NEST Example #1 where airline documents have no reference to route documents), then Index NESTs can be used efficiently. Index NESTs allow you to flip the direction of your nest clause.
Index NEST Example 1: List four
CREATE INDEX idx_ijoin ON `travel-sample`(airlineid) WHERE type="route"; SELECT * FROM `travel-sample` rte INNER NEST `travel-sample` aline ON KEY rte.airlineid FOR rte WHERE rte.type = "route" LIMIT 4;
If you generalize the same query, it looks like the following:
CREATE INDEX on-key-for-index-name rhs-expression (lhs-expression-key); SELECT projection-list FROM lhs-expression NEST rhs-expression ON KEY rhs-expression.lhs-expression-key FOR lhs-expression [ WHERE predicates ] ;
There are three important changes in the index scan syntax example above:
-
CREATE INDEXon theON KEYexpressionroute.airlineidto accessroutedocuments usingairlineid(which are produced on the LHS). -
The
ON KEY route.airlineid FOR airlineenables N1QL to use the indexroute.airlineid. -
Create any optional index, such as
route.airlinethat can be used onairline(LHS).
For index nests, the syntax uses ON KEY (singular) instead of ON KEYS (plural).
This is because Index NESTs' ON KEY expression must produce a scalar value; whereas Lookup NESTs' ON KEYS expression can produce either a scalar or an array value.
|
Syntax

[ nest-type ] NEST from-path [ [ AS ] alias ] ON KEY on-key-clause FOR for-clause
Arguments
- nest-type
-
[Optional; default is
LEFT INNER]LEFTorLEFT INNER-
For each nested object produced, both the left-hand and right-hand source objects must be non-MISSING and non-NULL.
LEFT OUTER-
For each nested object produced, only the left-hand source objects must be non-MISSING and non-NULL.
- from-path
-
Keyspace reference for right-hand side of an index nest. For details, see Keyspaces.
ASalias-
[Optional] To assign another name. For details, see AS Keyword.
ON KEYrhs-expression.lhs-expression-key-
- rhs-expression
-
Keyspace reference for the right-hand side of the index nest.
- lhs-expression-key
-
String or expression representing the attribute in
rhs-expressionreferencing the document key forlhs-expression.
FORlhs-expression-
Keyspace reference for the left-hand side of the index nest.
Index NEST Example 1: ON KEY ... FOR.
This example nests the airline routes for each airline after creating the following index. (Note that the index will not match if it contains a WHERE clause)
CREATE INDEX route_airline ON `travel-sample`(airlineid); SELECT * FROM `travel-sample` aline INNER NEST `travel-sample` rte ON KEY rte.airlineid FOR aline WHERE aline.type = "airline" LIMIT 1;
Results:
[
{
"aline": {
"callsign": "MILE-AIR",
"country": "United States",
"iata": "Q5",
"icao": "MLA",
"id": 10,
"name": "40-Mile Air",
"type": "airline"
},
"route": [
{
"airline": "Q5",
"airlineid": "airline_10",
"destinationairport": "HKB",
"distance": 118.20183585107631,
"equipment": "CNA",
"id": 46586,
"schedule": [
{
"day": 0,
"flight": "Q5188",
"utc": "12:40:00"
},
{
"day": 0,
"flight": "Q5630",
"utc": "21:53:00"
},
{
"day": 0,
"flight": "Q5530",
"utc": "07:47:00"
},
{
"day": 0,
"flight": "Q5132",
"utc": "01:10:00"
},
{
"day": 0,
"flight": "Q5746",
"utc": "20:11:00"
},
{
"day": 1,
"flight": "Q5413",
"utc": "08:07:00"
},
{
"day": 2,
"flight": "Q5263",
"utc": "17:39:00"
},
{
"day": 2,
"flight": "Q5564",
"utc": "01:55:00"
},
{
"day": 2,
"flight": "Q5970",
"utc": "00:09:00"
},
{
"day": 2,
"flight": "Q5295",
"utc": "21:24:00"
},
{
"day": 2,
"flight": "Q5051",
"utc": "04:41:00"
},
{
"day": 3,
"flight": "Q5023",
"utc": "00:16:00"
},
{
"day": 3,
"flight": "Q5554",
"utc": "11:45:00"
},
{
"day": 3,
"flight": "Q5619",
"utc": "22:22:00"
},
{
"day": 4,
"flight": "Q5279",
"utc": "23:19:00"
},
{
"day": 4,
"flight": "Q5652",
"utc": "13:35:00"
},
{
"day": 4,
"flight": "Q5631",
"utc": "17:53:00"
},
{
"day": 4,
"flight": "Q5105",
"utc": "21:54:00"
},
{
"day": 5,
"flight": "Q5559",
"utc": "01:19:00"
},
{
"day": 5,
"flight": "Q5600",
"utc": "17:36:00"
},
{
"day": 6,
"flight": "Q5854",
"utc": "22:59:00"
},
{
"day": 6,
"flight": "Q5217",
"utc": "11:58:00"
},
{
"day": 6,
"flight": "Q5756",
"utc": "06:32:00"
},
{
"day": 6,
"flight": "Q5151",
"utc": "15:14:00"
}
],
"sourceairport": "FAI",
"stops": 0,
"type": "route"
},
{
"airline": "Q5",
"airlineid": "airline_10",
"destinationairport": "FAI",
"distance": 118.20183585107631,
"equipment": "CNA",
"id": 46587,
"schedule": [
{
"day": 0,
"flight": "Q5492",
"utc": "17:00:00"
},
{
"day": 0,
"flight": "Q5357",
"utc": "09:44:00"
},
{
"day": 0,
"flight": "Q5873",
"utc": "00:01:00"
},
{
"day": 1,
"flight": "Q5171",
"utc": "00:59:00"
},
{
"day": 1,
"flight": "Q5047",
"utc": "10:57:00"
},
{
"day": 1,
"flight": "Q5889",
"utc": "14:51:00"
},
{
"day": 1,
"flight": "Q5272",
"utc": "18:36:00"
},
{
"day": 2,
"flight": "Q5673",
"utc": "21:30:00"
},
{
"day": 3,
"flight": "Q5381",
"utc": "20:01:00"
},
{
"day": 4,
"flight": "Q5261",
"utc": "18:37:00"
},
{
"day": 5,
"flight": "Q5755",
"utc": "23:43:00"
},
{
"day": 5,
"flight": "Q5544",
"utc": "16:04:00"
},
{
"day": 6,
"flight": "Q5400",
"utc": "10:46:00"
},
{
"day": 6,
"flight": "Q5963",
"utc": "13:53:00"
},
{
"day": 6,
"flight": "Q5195",
"utc": "03:03:00"
},
{
"day": 6,
"flight": "Q5653",
"utc": "22:58:00"
}
],
"sourceairport": "HKB",
"stops": 0,
"type": "route"
}
]
}
]
Appendix 1 - JOIN Types
| Join | Left-Hand Side (lhs) | Right-Hand Side (rhs) | Syntax | Example |
|---|---|---|---|---|
ANSI |
Any field or expr that produces a value that will be matched on the right-hand side. |
Anything that can have a proper index on the join expression. |
|
|
Lookup |
Must produce a Document Key for the right-hand side. |
Must have a Document Key. |
|
|
Index |
Must produce a key for the right-hand side’s index. |
Must have a proper index on the field or expr that maps to the Document Key of the left-hand side. |
|
*FOR a |
Appendix 2 - NEST Types
| NEST | Left-Hand Side (lhs) | Right-Hand Side (rhs) | Syntax | Example |
|---|---|---|---|---|
ANSI |
Any field or expr that produces a value that will be matched on the right-hand side. |
Anything that can have a proper index on the join expression. |
|
|
Lookup |
Must produce a Document Key for the right-hand side. |
Must have a Document Key. |
|
|
Index |
Must produce a key for the right-hand side index. |
Must have a proper index on the field or expr that maps to the Document Key of the left-hand side. |
|
|