Server Group Awareness
Individual server-nodes can be assigned to specific groups, within a Couchbase Cluster. This allows active vBuckets to be maintained on a different group from that of their corresponding replica vBuckets; so that if a group goes offline, bucket-data remains available on another group.
Understanding Server Group Awareness
Server Group Awareness provides enhanced availability. Specifically, it protects a cluster from large-scale infrastructure failure, through the definition of groups. Each group is created by an appropriately authorized administrator, and specified to contain a subset of the nodes within a Couchbase Cluster. Following group-definition and rebalance, the active vBuckets for any defined bucket are located on one group, while the corresponding replicas are located on another group. This allows Group Failover to be enabled, so that if an entire group goes offline, its replica vBuckets, which remain available on another group, can be automatically promoted to active status.
Groups should be defined in accordance with the physical distribution of cluster-nodes. For example, a group should only include the nodes that are in a single server rack, or in the case of cloud deployments, a single availability zone. Thus, if the server rack or availability zone becomes unavailable due to a power or network failure, Group Failover, if enabled, allows continued access to the affected data.
Data-protection is optimal when groups are assigned equal numbers of nodes, and vBuckets are therefore distributed such that none ever occupies the same group as its associated active vBucket. By contrast, when groups are not assigned equal numbers of nodes, rebalance can only produce a best effort redistribution of replica vBuckets: this may result in replica vBuckets occupying the same group as their associated active vBuckets; meaning that data may be lost if such a group becomes unavailable.
Server Group Awareness is only available in Couchbase Server Enterprise Edition.
General notes about Server Group Awareness:
-
Server Group Awareness only applies to the Data Service.
-
If a cluster contains only one node, or only one group of nodes, enabling Group Failover has no effect; meaning that failover can only be performed on a per-node basis.
-
Failover should be enabled for server groups only if three or more server groups have been established, and sufficient capacity exists to absorb the load of any failed-over group.
-
When you initialize a new Couchbase Server cluster, the first node, and all subsequent nodes, are automatically placed in a server group named Group 1. Once you create additional server groups, you are required to specify a server group when adding additional cluster nodes.
For information on failing over individual nodes, see Fail a Node over and Rebalance.
For information on vBuckets, see Buckets.
For information on the standard (non-Group-based) distribution of replica vBuckets across a cluster, see Availability.
Equal Groups
The following illustration shows how vBuckets are distributed across two groups; each group containing four of its cluster’s eight nodes.
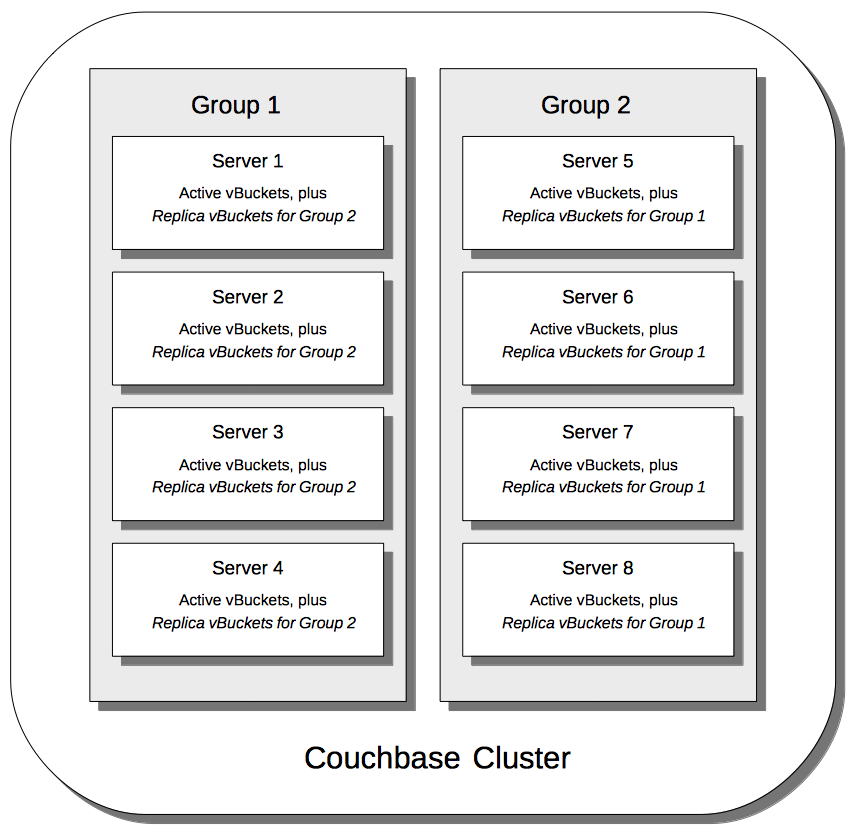
Note that Group 2 contains all the replica vBuckets that correspond to active vBuckets on Group 1; while conversely, Group 1 contains all the replica vBuckets that correspond to active vBuckets on Group 2.
Unequal Groups
The following illustration shows how vBuckets are distributed across two groups: Group 1 contains four nodes, while Group 2 contains five.
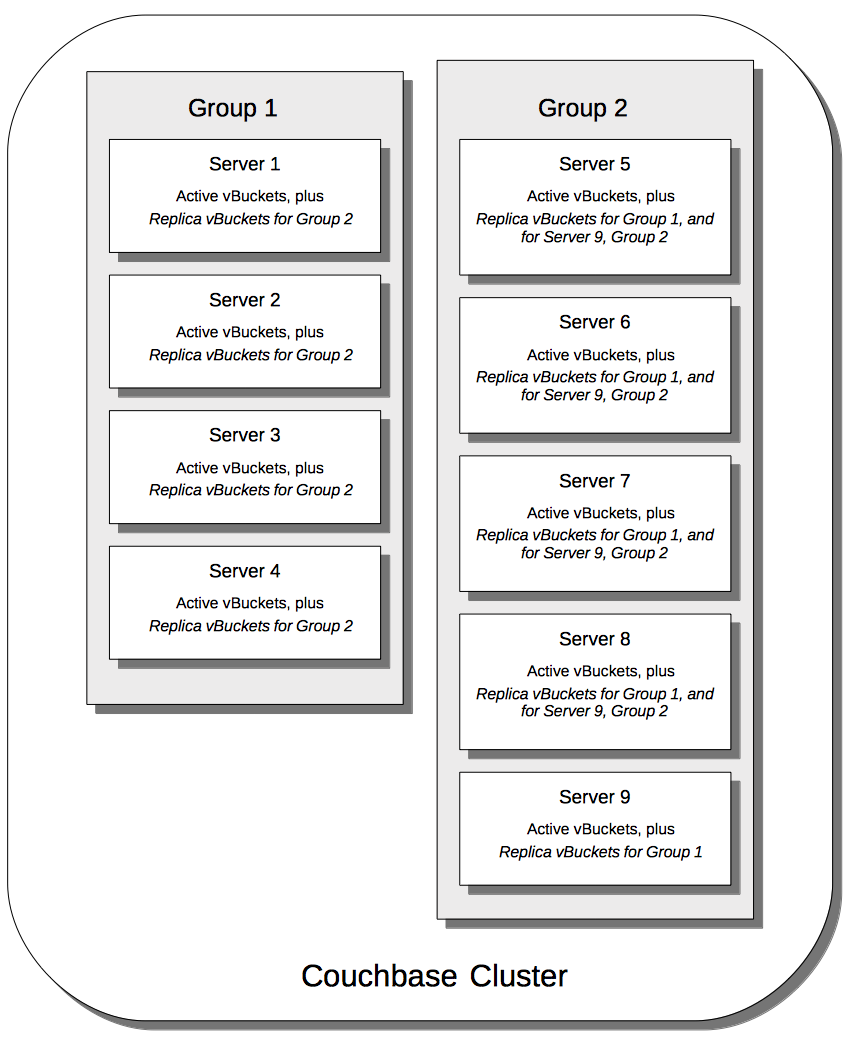
Group 1 contains all the replica vBuckets that correspond to active vBuckets on Group 2. However, since the groups contain unequal number of nodes, Group 2 not only contains all the replica vBuckets that correspond to active vBuckets on Group 1, but also contains all the replica vBuckets for its own additional node, Server 9 — the replicas for Server 9 being distributed across the other Group 2 nodes; which are Servers 5, 6, 7, and 8. Server 9 contains its own active vBuckets, plus replica vBuckets for Group 1.
This means that if Group 2 were to go offline, Group Failover would not preserve the replica vBuckets for Server 9, since these only existed on Group 2 itself.
Node-Failover Across Groups
When an individual node within a group goes offline, rebalance provides a best effort redistribution of replica vBuckets. This keeps all data available, but results in some data being no longer protected by the Groups mechanism. This is shown by the following illustration, in which Server 2, in Group 1, has gone offline, and a rebalance and failover have occurred.
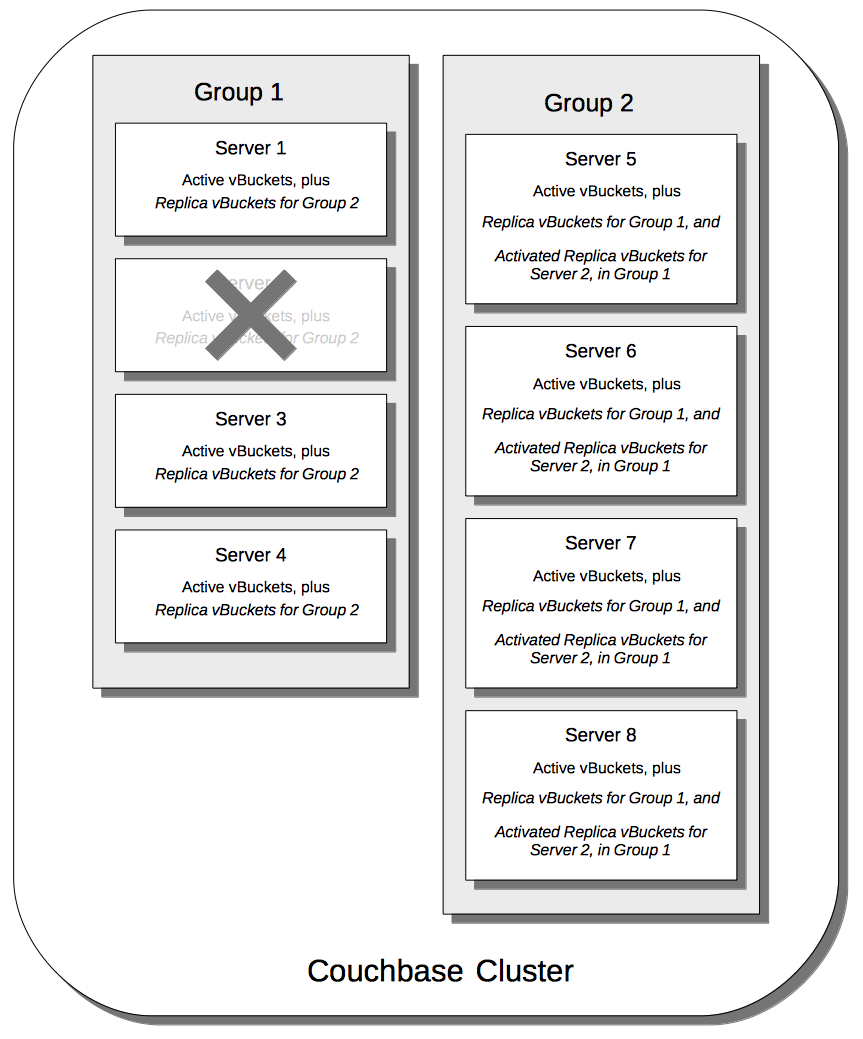
With the active vBuckets on Server 2 no longer accessible, the replica vBuckets for Server 2 have been promoted to active status, on the servers of Group 2. The data originally active on Server 2 is thereby kept available. Note, however, that if Group 2 were now to go offline, the data originally active on Server 2 would be lost, since it now exists only on Group 2 servers.
Defining Groups and Enabling Group Failover
To define and manage groups:
-
With Couchbase Web Console, see Manage Groups.
-
With CLI, see cli:cbcli/couchbase-cli-group-manage.adoc.
-
With the REST API, see Server Groups API.
To enable Group Failover:
-
With Couchbase Web Console, see Node Availability.
-
With CLI, see cli:cbcli/couchbase-cli-setting-autofailover.adoc.
-
With the REST API, see Enabling and Disabling Auto-Failover.