Graceful Failover
Graceful failover can be used to remove a Data Service node from a healthy cluster, in an orderly and controlled fashion.
Understanding Graceful Failover
Graceful failover allows Data Service node node to be safely removed from a cluster: if the node is running the Data Service, the Cluster Manager initiates data synchronization between nodes of the cluster before removal. This failover-type is commonly used for planned cluster-maintenance. Note that Graceful failover is only used for nodes running the Data Service: for nodes not running the Data Service, hard failover is used.
Graceful failover removes active vBuckets, one at a time, from the node to be removed. During this process, for each active vBucket, first, ongoing operations are completed; next, the state of a corresponding replica vBucket elsewhere on the cluster is synchronized to match that of the active vBucket undergoing removal; finally, the replica is promoted to active status, and begins serving data; while the old active vBucket is demoted, to dead status. All data continues to be available, without application performance-loss.
Graceful failover may take longer than hard failover, especially if performed while the cluster is under a high write-load.
Graceful failover should be used only when all nodes in the cluster are health, and when each bucket in the cluster has all 1024 active vBuckets available, and also has at least one full set of 1024 replica vBuckets.
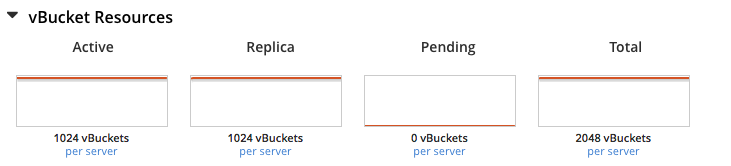
vBucket status can be ascertained through observation of the vBucket Resources section of the Statistics provided for the bucket in Couchbase Web Console: the active and replica vBucket graphs indicate the number of vBuckets available for the bucket.
In consequence of these requirements, in a 7-node cluster, if a bucket is configured for:
-
One replica, one node can be gracefully failed over
-
Two replicas, two nodes can be gracefully failed over
-
Three replicas, three nodes can be gracefully failed over
A graceful failover can be halted, mid-process. If it is subsequently restarted, it continues exactly from where it left off. If it is not subsequently restarted, the cluster must be rebalanced, in order restore the cluster to its former state.
Advantages and Disadvantages
Graceful failover offers the following advantages:
-
Maintenance can be completed faster than with a remove and rebalance; especially when Delta Node Recovery is used to add the node back subsequently.
-
Graceful failover is less resource-intensive than hard failover; since vBuckets simply have their status changed from replica to active, and do not need to be copied.
Graceful failover, however, might entail the following disadvantages:
-
Temporary loss of resiliency. By promoting the replica vBuckets to active on the remaining nodes, the cluster does not have the full accompaniment of replica vBuckets necessary to handle any additional node failures.
-
Temporary loss of performance. Depending on cluster size and workload, replica-data may not be in managed cache (when under memory pressure, Couchbase Server ejects) replica data before active data). Therefore, replica-data will need to be accessed from disk, incurring latency.
Graceful Failover Example
Given:
-
A fully healthy cluster containing four nodes, each of which runs the Data Service.
-
One replica for each bucket, resulting in 256 active and 256 replica vBuckets for each bucket, on each of the four nodes.
-
The requirement to remove one of the Data Service nodes (node 4) on which active vBucket 762 resides.
-
Graceful failover.
The following occur:
-
The Cluster Manager take steps to ensure that active vBucket #762 is exactly in sync with replica vBucket #62, which resides on node 2.
-
The Cluster Manager coordinates a takeover by node 2 of vBucket 762, promoting vBucket 762 to active, on node 2; and demoting the old active vBucket on node 4, to dead. Note that this leaves the cluster with no replica for vBucket 762 until the next rebalance or Delta Node Recovery.
-
The cluster map is updated, so that subsequent reads and writes go to the correct location for vBucket 762, now on node 2.
-
The same steps are repeated for the remaining 255 vBuckets of the bucket on this node, one at a time; and are likewise repeated for all remaining vBuckets of other buckets.