Covering Indexes
When an index includes the actual values of all the fields specified in the query, the index covers the query and does not require an additional step to fetch the actual values from the data service. An index, in this case, is called a covering index and the query is called a covered query. As a result, covered queries are faster and deliver better performance.
The following diagram illustrates the query execution work flow without covering indexes:
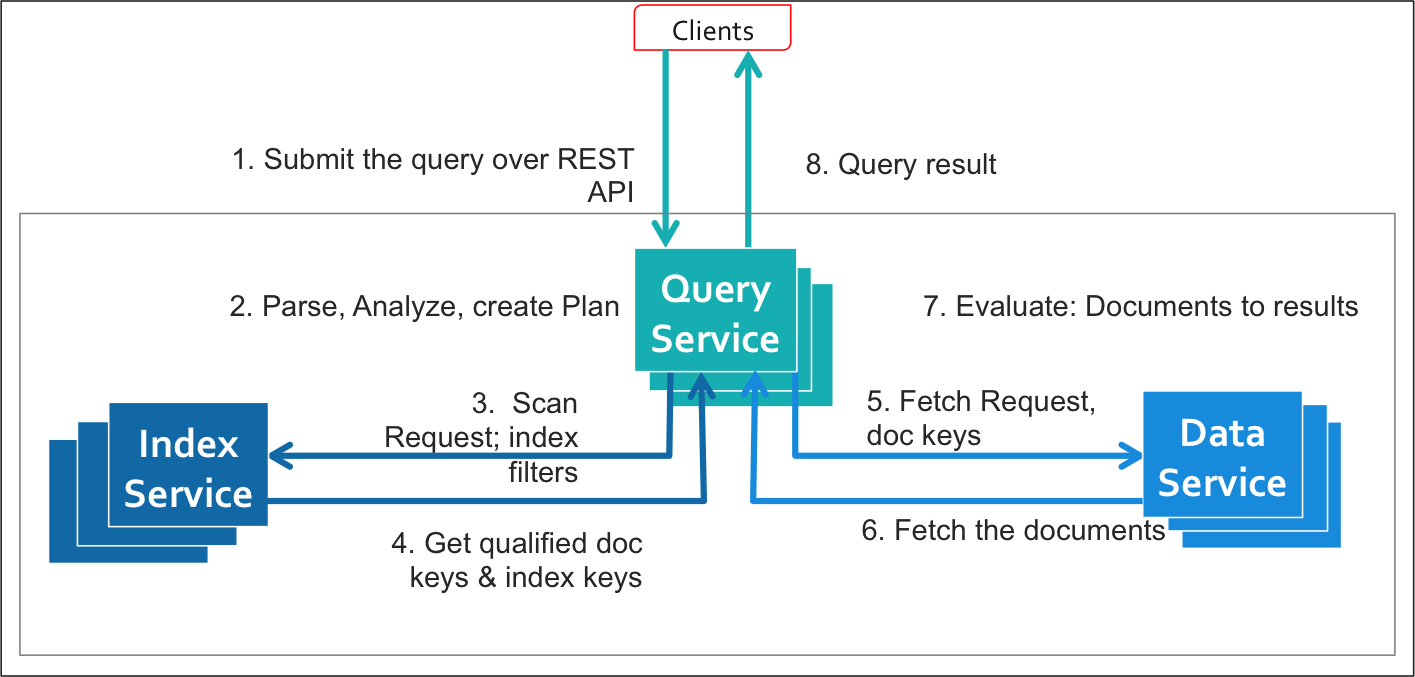
The following diagram illustrates the query execution work flow with covering indexes:
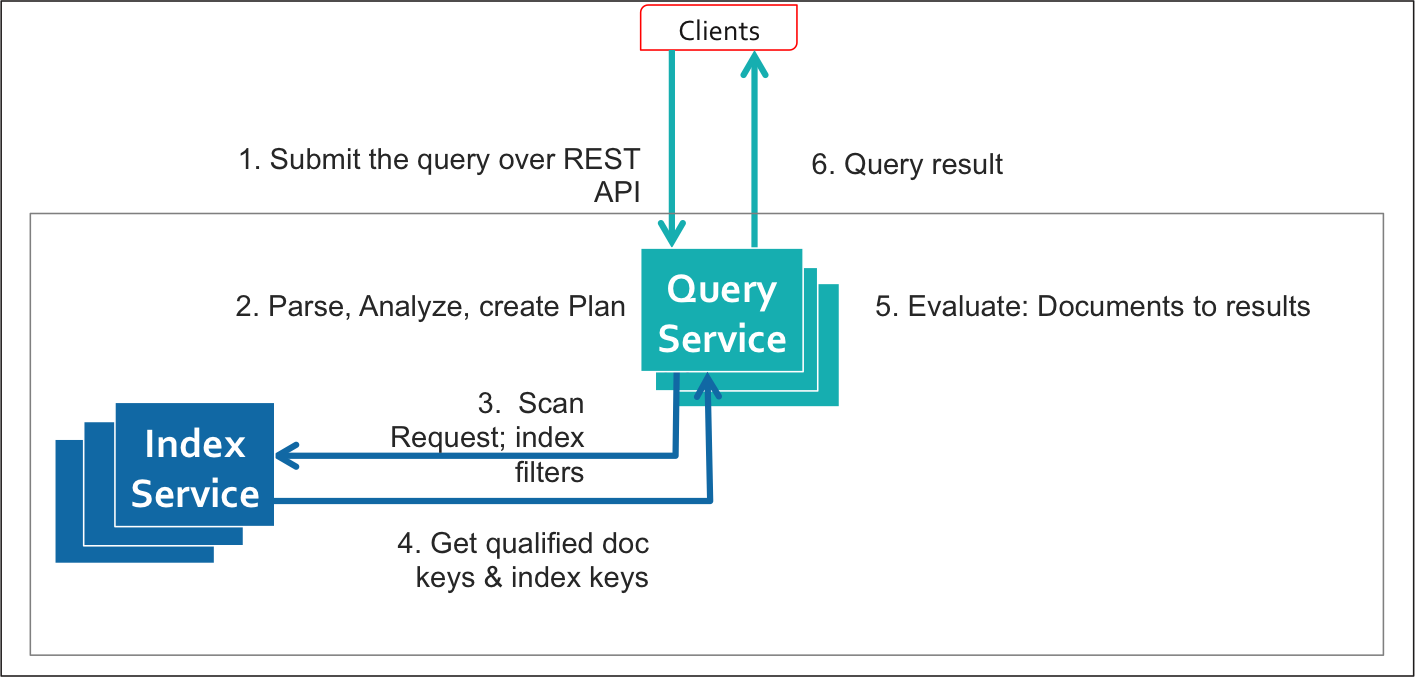
As you can see in the second diagram, a well designed query that uses a covering index avoids the additional steps to fetch the data from the data service. This results in a considerable performance improvement.
The examples on this page use the travel-sample and default keyspaces and need to be enabled before using them.
See settings:install-sample-buckets.adoc for details.
|
You can see the query execution plan using the EXPLAIN statement.
When a query uses a covering index, the EXPLAIN statement shows that a covering index is used for data access, thus avoiding the overhead associated with key-value document fetches.
Consider a simple index, idx_state, on the attribute state in the travel-sample keyspace:
CREATE INDEX idx_state on `travel-sample` (state,type) USING GSI;
If we select state from the `travel-sample` keyspace, the actual values of the field state that are to be returned are present in the index idx_state, and avoids an additional step to fetch the data.
In this case, the index idx_state is called a covering index and the query is a covered query.
EXPLAIN SELECT state FROM `travel-sample` WHERE type="hotel" AND state = "CA";
Results:
[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
"covers": [ / details of using Covered Index
"cover ((`travel-sample`.`state`))",
"cover ((`travel-sample`.`type`))",
"cover ((meta(`travel-sample`).`id`))"
],
"index": "idx_state", / Using the Index we created
"index_id": "286838921fc14273",
"index_projection": {
"entry_keys": [
0,
1
]
},
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"CA\"",
"inclusion": 3,
"low": "\"CA\""
},
{
"high": "\"hotel\"",
"inclusion": 3,
"low": "\"hotel\""
}
]
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Filter",
"condition": "((cover ((`travel-sample`.`type`)) = \"hotel\") and (cover ((`travel-sample`.`state`)) = \"CA\"))"
},
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "cover ((`travel-sample`.`state`))" / using Covered Index
}
]
},
{
"#operator": "FinalProject"
}
]
}
}
]
},
"text": "SELECT state FROM `travel-sample` WHERE type=\"hotel\" AND state = \"CA\";"
}
]
If you modify the query to select the state and city from the `travel-sample` bucket using the same index idx_state, the index does not contain the values of the city field to satisfy the query, and hence a key-value fetch is performed to retrieve this data.
EXPLAIN SELECT state,city FROM `travel-sample` USE INDEX (idx_state) WHERE type="hotel" AND state = "CA";
Results:
[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan2",
/ not using Covered Index
"index": "idx_state", / using the Index we created
"index_id": "286838921fc14273",
"index_projection": {
"primary_key": true
},
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"CA\"",
"inclusion": 3,
"low": "\"CA\""
},
{
"high": "\"hotel\"",
"inclusion": 3,
"low": "\"hotel\""
}
]
}
],
"using": "gsi"
},
{
"#operator": "Fetch",
"keyspace": "travel-sample",
"namespace": "default"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Filter",
"condition": "(((`travel-sample`.`type`) = \"hotel\") and ((`travel-sample`.`state`) = \"CA\"))"
},
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "(`travel-sample`.`state`)" / not using Covered Index
},
{
"expr": "(`travel-sample`.`city`)"
}
]
},
{
"#operator": "FinalProject"
}
]
}
}
]
},
"text": "SELECT state,city FROM `travel-sample` WHERE type=\"hotel\" AND state = \"CA\";"
}
]
To use a covering index for the modified query, you must define an index with the state and type and city attributes before executing the query.
CREATE INDEX idx_state_city on `travel-sample` (state, type, city) USING GSI;
|
CREATE INDEX index1 ON bucket(attribute1) WHERE attribute2 = "value"; SELECT attribute1 FROM bucket WHERE attribute2 = "value" AND attribute1 IS NOT MISSING; |
Covering indexes are applicable to secondary index scans and can be used with view and global secondary indexes (GSI). Queries with expressions and aggregates benefit from covering indexes.
| You cannot use multiple GSI indexes to cover a query. You must create a composite index with all the required fields for the query engine to cover by GSI and not require reading the documents from the data nodes. |
The following queries can benefit from covering indexes.
Try these statements using cbq to see the query execution plan.
Expressions and Aggregates
EXPLAIN SELECT MAX(country) FROM `travel-sample` WHERE city = "Paris";
EXPLAIN SELECT country || city FROM `travel-sample` USE INDEX (idx_country_city) WHERE city = "Paris";
UNION/INTERSECT/EXCEPT
SELECT country FROM `travel-sample` WHERE city = "Paris"
UNION ALL
SELECT country FROM `travel-sample` WHERE city = "San Francisco";
Sub-queries
SELECT * FROM ( SELECT country FROM `travel-sample` WHERE city = "Paris" UNION ALL SELECT country FROM `travel-sample` WHERE city = "San Francisco" ) AS newtab;
SELECT in INSERT statements
INSERT INTO `travel-sample`(KEY k, VALUE city) SELECT country, city FROM `travel-sample` WHERE city = "Paris";
Arrays in WHERE clauses
First, create a new index, idx_array.
CREATE INDEX idx_array ON `travel-sample`(a, b);
Then, run the following query:
SELECT b FROM `travel-sample` WHERE a = [1, 2, 3, 4];
Collection Operators: FIRST, ARRAY, ANY, EVERY, and ANY AND EVERY
Since the default bucket is empty by default, let’s first insert the following documents into the default bucket:
INSERT INTO default VALUES ("account-customerXYZ-123456789",
{ "accountNumber": 123456789,
"docId": "account-customerXYZ-123456789",
"code": "001",
"transDate":"2016-07-02" } );
INSERT INTO default VALUES ("codes-version-9",
{ "version": 9,
"docId": "codes-version-9",
"codes": [
{ "code": "001",
"type": "P",
"title": "SYSTEM W MCC",
"weight": 26.2466
},
{ "code": "166",
"type": "P",
"title": "SYSTEM W/O MCC",
"weight": 14.6448 }
]
});
Create an index, idx_account_customer_xyz_transDate:
CREATE INDEX idx_account_customer_xyz_transDate
ON default(SUBSTR(transDate,0,10),code)
WHERE code != "" AND meta().id LIKE "account-customerXYZ%";
Then, run the following query:
SELECT SUBSTR(account.transDate,0,10) AS transDate, AVG(codes.weight) AS avgWeight
FROM default account
JOIN default codesDoc ON KEYS "codes-version-9"
LET codes = FIRST c FOR c IN codesDoc.codes WHEN c.code = account.code END
WHERE account.code != "" AND meta(account).id LIKE "account-customerXYZ-%"
AND SUBSTR(account.transDate,0,10) >= "2016-07-01" AND SUBSTR(account.transDate,0,10) < "2016-07-03"
GROUP BY SUBSTR(account.transDate,0,10);
Results:
[
{
"avgWeight": 26.2466,
"transDate": "2016-07-02"
}
]
The EXPLAIN statement for the above query shows that the index covers the query.
Prepared statements also benefit from using covering indexes.